资源:4core/8g*2台,最终结果:1500并发/s时,tps约9000,cpu占用60%作用,mem占用6g左右
1、flume
本次日志收集采用Apache高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统flume,版本1.9,官方文档:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
该中间件构件单元为agent,数据传输单位为event,如下图所示:
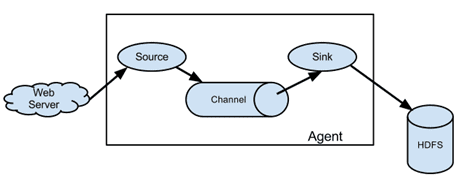
它支持各种丰富的source、channel、sink组件,还可以用户自定义开发,文档友好,
特别适用于流式数据比如日志数据的处理。其中,source 负责数据的产生或搜集,从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道Channel。Channel 是一种短暂的存储容器,负责数据的存储持久化,可以持久化到jdbc,file,memory等,将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,对事物天然支持。可以把channel看成是一个队列,队列的优点是先进先出,放好后尾部一个个event出来,Flume比较看重数据的传输,因此几乎没有数据的解析预处理,仅仅是数据的产生,封装成event然后传输。sink 负责数据的转发,它从channel消费数据(events)并将其传递给目标地,目标地可能是另一个sink,也可能是hdfs、file、自定义等。
2、Kafka:
在上一版本中,进行了如下尝试:①为了提高tps,尝试了使用基于内存的flume-memoryChannel,但是由于峰值流量的不确定经常导致内存溢出,以及采用内存作为持久带来的数据安全性问题,故该方式排除。②使用基于fileChannel的flume-agent单元,采用文件通道来进行持久化,解决了内存溢出的问题,也解决了数据安全性的问题,但是由于数据落地文件带来的高磁盘I/o、source和sink的锁竞争等弊端,直接导致了tps急剧下降,故该方案也不完美。
本次版本,引入分布式消息存储中间件kafka来存储消息,kafka分布式、多副本的机制保证了数据的安全性,同时消息进行了分区存储,采用多个consumer进程来同时消费消息,另外,kafka的引入,消除了结构耦合,解决了flume单元结构中source、sink锁竞争的问题,同时,基于kafka的数据安全和蓄洪特性,控制了出口流量,故后面的结构均可放心地采用内存通道,保证了系统的吞吐量。
3、结构意图:
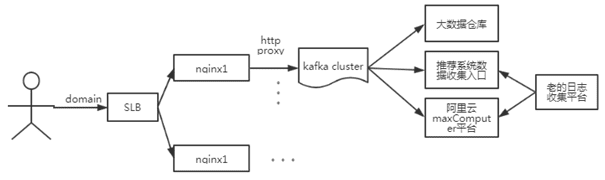
4、日志流向示意图:
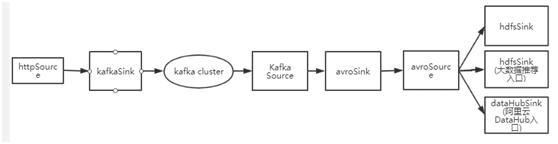
详细结构及日志流向示意图见附件“日志收集结构示意图”。
5、可用和容错性:
①目前采用2节点并行部署,由nginx交叉代理,轮询负载,保证可用性;
②上报到代理服务器的请求将被代理到kafkaSink入口,以2 partation,多副本机制的消息存储在kafka集群中,保证了数据的高可靠性,同时kafka能对流量进行蓄洪,削峰,基于此,在采用kafka source消费kafka中的消息时,由于kafka对流量峰值进行了缓冲,控制了出口的流量值,故agent采用基于内存的通道memoryChannel,在能保证内存安全的情况下提高消费的吞吐量,经过试验,达到当前系统吞吐量指标时,末端数据sink均需要2个(详见日志收集架构),才能保证kafka中消息不堆积。
6、准确性:
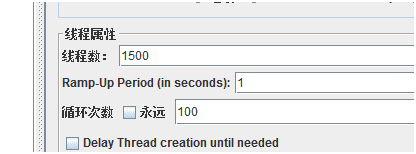
jmeter测试1500并发/秒,循环100次,post了15w条数据
节点1文件中75002条;
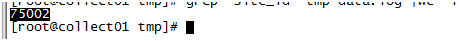
节点2文件中共74998条,共15w条。
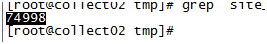
7、可扩展性:
目前部署在两台节点,基于服务器资源情况和目标tps,每节点启用1个端口HTTPSource监听日志上报,采用代理服务轮询负载到两台节点,后续日志量大了之后还可以对代理节点或flume支路进行扩展,以降低各支路的负载。同时,后续某个目的端如果下线,可以直接将该anent进程杀掉即可。
8、关键配置片段:
①nginx均衡负载到两个节点

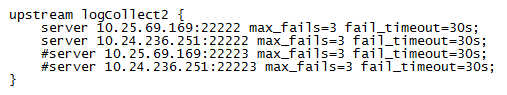
②kafkaSink多路扇出(复制)到多个目的地。

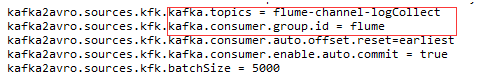
9、性能自测:
因为slb有tps 1000的限制(运维目前不好评估并发量有多大,成本考虑,目前1000配置,后续扩容),jmeter压力测试负载在其中一台nginx的公网地址,http://公网ip/logCollect2,1500并发/秒,2节点并行稳定时tps约9000
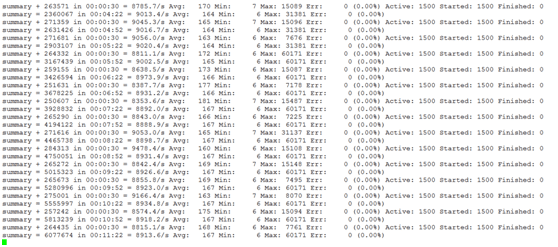
稳定状态下,消息堆积情况:

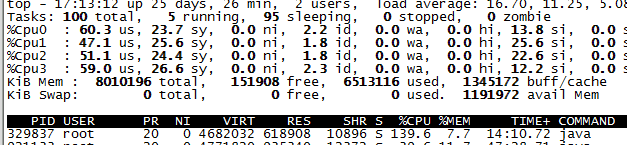
压测稳定情况下资源使用情况
node1:
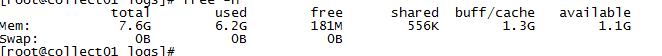
node2:
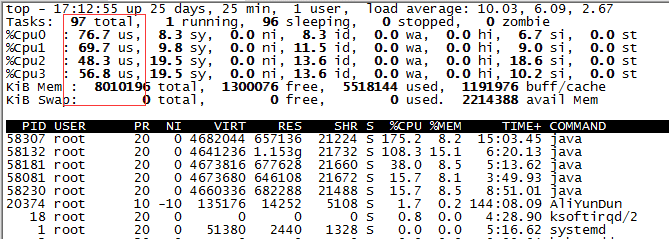
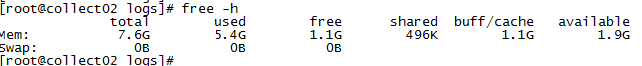
当前服务器资源在该压力下内存占用有些高。
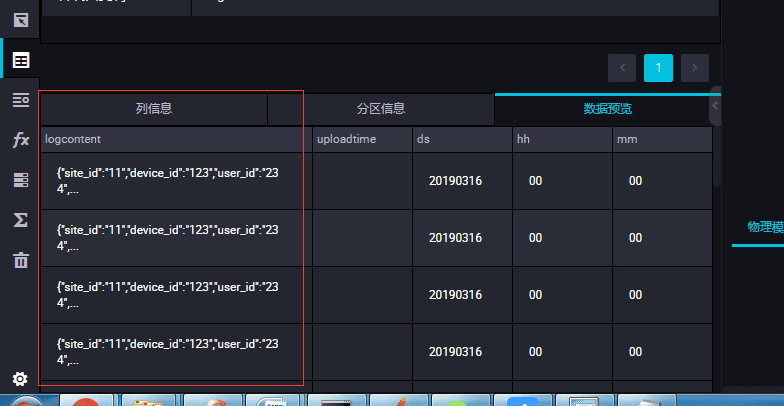
10、数据落地展示:
①自研数仓数据落地情况:
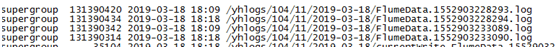
②推荐系统数据落地情况:
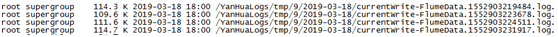
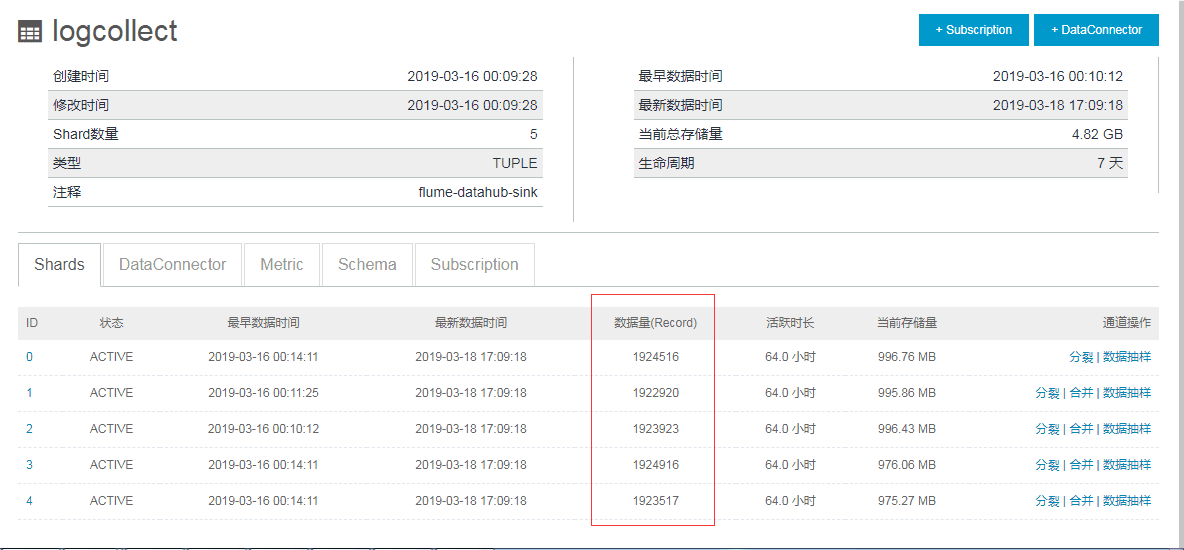
③阿里云datahub数据落地和数据归档到maxCompute
11、缺点:
①虽然几乎所有的大数据收集均不可能做到绝对实时,但由于本例数据流向目的稍多,结构稍复杂,流量峰值时数据实时性会有牺牲。
②由于引入kafka集群进行流量缓冲,系统维护复杂度增高,需要额外维护kafka集群、zookeeper集群。
本文地址:http://www.45fan.com/a/question/100310.html