怎么样在MySQL中使用、in与union all在查询命令下的效率对比?
OR、in和union all 查询效率到底哪个快?
网上很多的声音都是说union all 快于 or、in,因为or、in会导致全表扫描,他们给出了很多的实例。
但真的union all真的快于or、in?
EXPLAIN SELECT * from employees where employees.first_NAME ='Georgi' UNION ALL SELECT * from employees where employees.first_NAME ='Bezalel'
这条语句执行结果481条,执行时间为0.35s
PRIMARY employees ALL 300141 Using where
UNION employees ALL 300141 Using where
UNION RESULT <union1,2> ALL
explain SELECT * FROM employees WHERE employees.first_name IN ('Georgi','Bezalel')
这条语句的执行结果时间为0.186s
SIMPLE employees ALL 300141 Using where explain SELECT * FROM employees WHERE employees.first_name ='Georgi' or employees.first_name='Bezalel'
这条语句的执行结果和in的结果差不多
难道是网上的说法有误?难道和索引有关?在firstname上建立了一个索引
重新执行
union的执行执行计划如下,执行时间为0.004s
PRIMARY employees ref index_firstname index_firstname 44 const 253 Using where UNION employees ref index_firstname index_firstname 44 const 228 Using where UNION RESULT <union1,2> ALL
in的执行计划如下,执行时间也为0.004s
SIMPLE employees range index_firstname index_firstname 44 481 Using where
or的执行计划如下,执行时间也为0.004s
SIMPLE employees range index_firstname index_firstname 44 481 Using where
感觉性能差不多埃但是注意执行计划中的type,ref要好于range哦(ref为非唯一性索引扫描,range为索引范围扫描)
突然感觉好像和网上说的差不多了,但是第一个语句走了两个ref扫描 会不会效率比走一次range的扫描低埃
要不我再试试主键,这个是唯一的,会不会和网上的效果一直呢?
EXPLAIN SELECT * FROM employees WHERE employees.EMP_NO=100001 UNION ALL SELECT * FROM employees WHERE employees.EMP_NO=101100
union的执行计划如下
PRIMARY employees const PRIMARY PRIMARY 4 const 1 UNION employees const PRIMARY PRIMARY 4 const 1 UNION RESULT <union1,2> ALL EXPLAIN SELECT * FROM employees WHERE employees.EMP_NO IN (100001 ,101100)
in的执行计划如下
SIMPLE employees range PRIMARY PRIMARY 4 2 Using where EXPLAIN SELECT * FROM employees WHERE employees.EMP_NO=100001 OR emp_no=101100
or的执行计划如下
SIMPLE employees range PRIMARY PRIMARY 4 2 Using where
感觉结果和第二个实验还是差不多。
下面本文就采用实例来探讨在实际的查询命令下它们之间的效率对比究竟如何。
1:创建表,插入数据、数据量为1千万【要不效果不明显】。
drop table if EXISTS BT; create table BT( ID int(10) NOT NUll, VName varchar(20) DEFAULT '' NOT NULL, PRIMARY key( ID ) )ENGINE=INNODB;
该表只有两个字段 ID为主键【索引页类似】,一个是普通的字段。(偷懒就用简单的表结构呢)
向BT表中插入1千万条数据
这里我写了一个简单的存储过程【所以你的mysql版本至少大于5.0,俺的版本为5.1】,代码如下。
注意:最好
INSERT INTO BT ( ID,VNAME ) VALUES( i, CONCAT( 'M', i ) );---1
修改为
INSERT INTO BT ( ID,VNAME ) VALUES( i, CONCAT( 'M', i, 'TT' ) );---2
修改原因在
非索引列及VNAME使用了联合进行完全扫描请使用1 。
非索引列及VNAME使用了全表扫描请使用2 。
DROP PROCEDURE IF EXISTS test_proc; CREATE PROCEDURE test_proc() BEGIN declare i int default 0; set autocommit = 0; while i<10000000 do INSERT INTO BT ( ID,VNAME ) VALUES( i, CONCAT( 'M', i ) ); set i = i+1; if i%2000 = 0 then commit; end if; end while; END;
就不写注释呢,挺简单的。
存储过程是最好设置下innob的相关参数【主要和日志、写缓存相关这样能加快插入】,俺没有设置插入1千万条数据插了6分钟。
部分数据如下:1千万数据类似
2:实战
2.1 :分别在索引列上使用 or、in、union all
我们创建的表只有主键索引,所以只能用ID做查询呢。我们查 ID 为 98,85220,9888589的三个数据各个耗时如下:
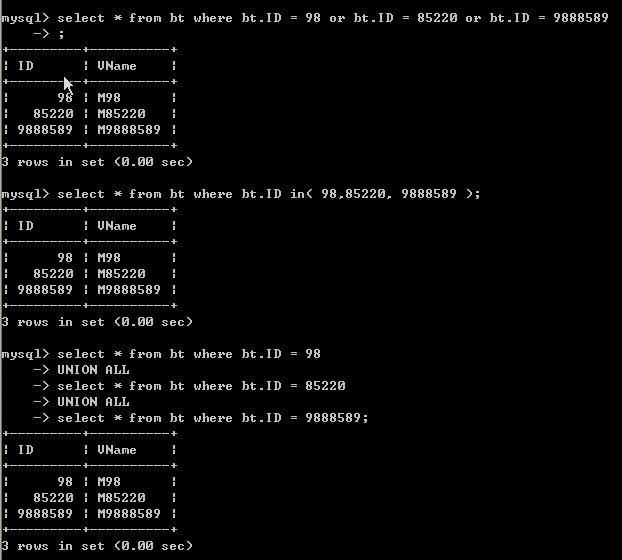
时间都为0.00,怎么会这样呢,呵呵所有查询都是在毫秒级别。
我使用其他的工具--EMS SQL Manager for mysql
查询显示时间为
93 ms, 94ms,93 ms,时间相差了多少几乎可以忽略。
然后我们在看看各自的执行计划
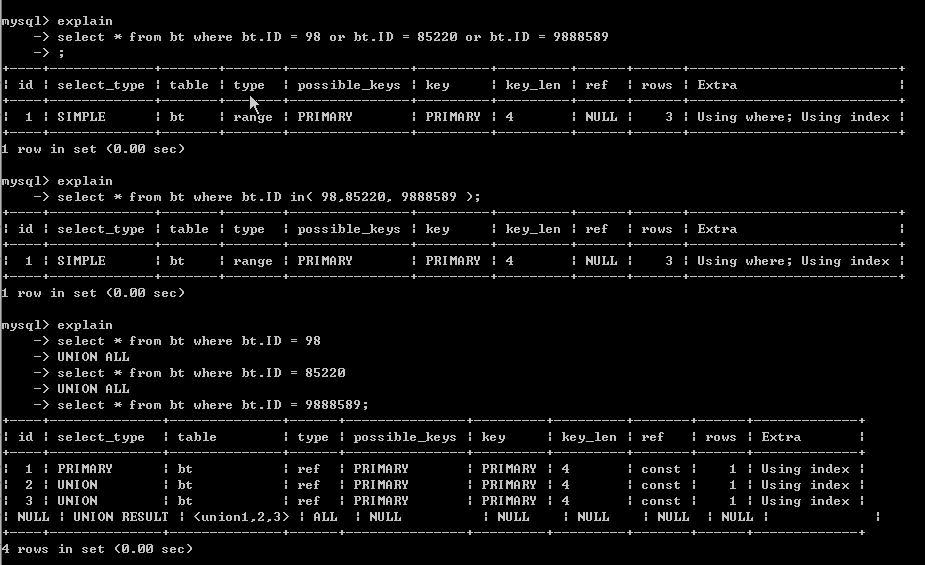
这里要注意的字段type 与ref字段
我们发现union all 的所用的 type【type为显示连接使用了何种类型】 为ref 而or和in为range【ref连接类型优于range,相差不了多少】,而查询行数都一样【看rows字段都是为3】。
从整个的过程来看,在索引列使用常数or及in和union all查询相差不了多少。
但为什么在有的复杂查询中,再索引列使用or及in 比union all 速度慢很多呢,这可能是你的查询写的不够合理,让mysql放弃索引而进行全表扫描。
2.2:在非索引列中使用 or、in及union all。
我们查 VNAME 为 M98,M85220,M9888589的三个数据各个耗时如下:
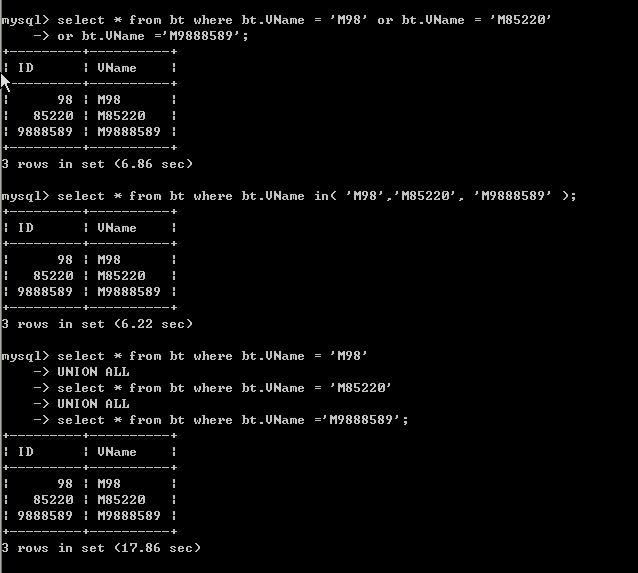
我们发现为啥union all查询时间几乎为 or 和in的三倍。
这是为什么呢,我们先不说,先看看三个的查询计划。
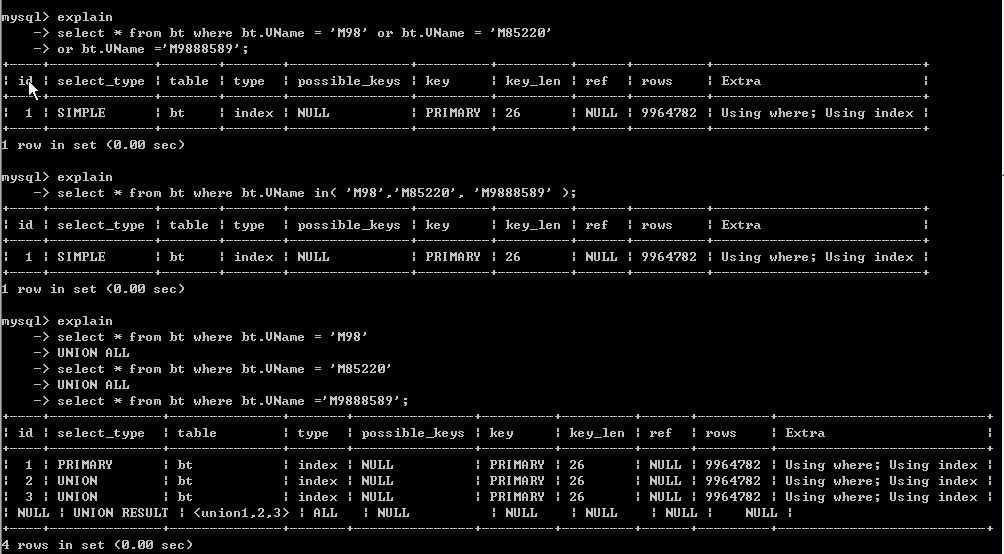
这里我们发现计划几乎一样。
但我们要注意扫描的此时对于 or及in 来说 只对表扫描一次即rows是列为9664782。
而对于union all 来说对表扫描了三次即rows的和为9664782*3。
这也是为什么我们看到union all 为几乎为三倍的原因。
备注: 如果使用存储过程使用第二sql该执行计划所有的type列 为 all,其实这个是我最想演示的,但现在已经快写完毕了才发现问题将错就错呢。
3:总结
3.1:不要迷信union all 就比 or及in 快,要结合实际情况分析到底使用哪种情况。
3.2:对于索引列来最好使用union all,因复杂的查询【包含运算等】将使or、in放弃索引而全表扫描,除非你能确定or、in会使用索引。
3.3:对于只有非索引字段来说你就老老实实的用or 或者in,因为 非索引字段本来要全表扫描而union all 只成倍增加表扫描的次数。
3.4:对于及有索引字段【索引字段有效】又包含非索引字段来时,按理你也使用or 、in或者union all 都可以,
但是我推荐使用or、in。
如以下查询:
select * from bt where bt.VName = 'M98' or bt.id ='9888589' select * from bt where bt.VName = 'M98' UNION ALL select * from bt where bt.id = '9888589'
该两个查询速度相差多少 主要取决于 索引列查询时长,如索引列查询时间太长的话,那你也用or或者in代替吧。
3.5: 以上主要针对的是单表,而多表联合查询来说,考虑的地方就比较多了,比如连接方式,查询表数据量分布、索引等,再结合单表的策略选择合适的关键字。
本文地址:http://www.45fan.com/a/question/41099.html