怎么样通过编写Ruby脚本对Twitter用户的数据进行深度挖掘?
Twitter以及一些API
尽管早期的网络涉及的是人-机器的交互,但现在的网络已涉及机器-机器之间的交互,这种交互是使用web服务来支持的。大部分受欢迎的网站都有这样的服务存在——从各种各样的Google服务到LinkedIn、Facebook和Twitter等。通过web服务创建的API,外部的应用可以查询或是操纵网站上的内容。
web服务可以使用多种方式来实现。目前最流行的做法之一是表述性状态转移(Representational State Transfe, REST)。REST的一种实现是通过为人熟知的HTTP协议,允许HTTP作为RESTful架构的媒介存在(使用诸如GET、PUT、POST、DELETE一类的标准HTTP操作)。Twitter的API是作为这一媒介之上的一个抽象来进行开发的。在这一做法中,没有涉及REST、HTTP或是XML或JSON一类的数据格式的知识,而是代之以清晰地整合到了Ruby语言中的基于对象的接口。
Ruby和Twitter的一个快速展示
让我们来探讨一下如何在Ruby中使用Twitter API。首先,我们需要获取所需的资源,如果你像我一样在用Ubuntu Linux®的话,就使用apt框架。
若要获取最新的完整的Ruby分发版本(大约13MB的下载量),使用这一命令行:
$ sudo apt-get install ruby1.9.1-full
接着使用gem实用程序来抓取Twitter gem:
$ sudo gem install twitter
现在你已经有了这一步骤所需的一切了,我们继续,测试一下Twitter的包装器。这一示例使用一个名为交互式的Ruby外壳(Interactive Ruby Shell,IRB)的外壳程序,该外壳程序允许实时地执行Ruby命令以及使用语言进行实验。IRB有着非常多的功能,不过我们只用它来做一些简单的实验。
清单1展示了与IRB的一个会话,该会话被分成了三段以便于阅读。第一段(001和002行)通过导入必需的运行时元素来做好环境方面的准备(require方法加载并执行指定的库)。接下来的一段(003行)说明的是使用Twitter gem来显示从IBM® developerWorks®发出的最新tweet消息。如所展示的那样,使用Client::Timeline模块的user_timeline方法来显示一条消息,这第一个例子说明了Ruby的“链方法”的功能。user_timeline方法返回一个有着20条消息的数组,接着链入到方法first中,这样做是为了从数组中提取出第一条消息(first是Array类的一个方法),接着从这一条消息中提取出文本字段,通过puts方法把它放到输出中。
接下来的一段(004行)使用了用户定义的位置字段,这是一个不限形式的字段,用户可以在其中提供有用的或是无用的位置信息。在这一例子中,User模块抓取了位置字段所限定的用户信息。
最后一段(从005行开始)研究了Twitter::Search模块,这一搜索模块提供了极其丰富的用来搜索Twitter的接口。在这一例子中,首先是创建一个搜索实例(005行),接着在006行指定一个搜索,搜 LulzSec用户在最近发出的包含了why这一词的消息,结果列表已经过删减和编辑。搜索设置会一直存在在那里,因为搜索实例保持着所定义的过滤条件,你可以通过执行search.clear来清除这些过滤条件。
清单1. 通过IRB来实验Twitter API
$ irb irb(main):001:0> require "rubygems" => true irb(main):002:0> require "twitter" => true irb(main):003:0> puts Twitter.user_timeline("developerworks").first.text dW Twitter is saving #IBM over $600K per month: will #Google+ add to that?> http://t.co/HiRwir7 #Tech #webdesign #Socialmedia #webapp #app => nil irb(main):004:0> puts Twitter.user("MTimJones").location Colorado, USA => nil irb(main):005:0> search = Twitter::Search.new => #<Twitter::Search:0xb7437e04 @oauth_token_secret=nil, @endpoint="https://api.twitter.com/1/", @user_agent="Twitter Ruby Gem 1.6.0", @oauth_token=nil, @consumer_secret=nil, @search_endpoint="https://search.twitter.com/", @query={:tude=>[], :q=>[]}, @cache=nil, @gateway=nil, @consumer_key=nil, @proxy=nil, @format=:json, @adapter=:net_http< irb(main):006:0> search.containing("why").to("LulzSec"). result_type("recent").each do |r| puts r.text end @LulzSec why not stop posting <bleep> and get a full time job! MYSQLi isn't hacking you <bleep>. ... irb(main):007:0>
接下来,我们来看一下Twitter中的用户的模式,你也可以通过IRB来实现这一点,不过我重排了结果的格式,以便简化对Twitter用户的内部结构的说明。清单2给出了用户结构的输出结果,这在Ruby中是一个Hashie::Mash。这一结构很有用,因为其允许对象有类方法的哈希键访问器(公开的对象)。正如你从清单2中看到的那样,这一对象包含了丰富的信息(用户特定的以及渲染的信息),其中包括了当前的用户状态(带有地理编码信息)。一条tweet消息中也包含了大量的信息,你可以使用user_timeline类来轻松地可视化生成这一信息。
清单2. Twitter用户的内部解析结构(Ruby视角)
irb(main):007:0> puts Twitter.user("MTimJones") <#Hashie::Mash contributors_enabled=false created_at="Wed Oct 08 20:40:53 +0000 2008" default_profile=false default_profile_image=false description="Platform Architect and author (Linux, Embedded, Networking, AI)." favourites_count=1 follow_request_sent=nil followers_count=148 following=nil friends_count=96 geo_enabled=true id=16655901 id_str="16655901" is_translator=false lang="en" listed_count=10 location="Colorado, USA" name="M. Tim Jones" notifications=nil profile_background_color="1A1B1F" profile_background_image_url="..." profile_background_image_url_https="..." profile_background_tile=false profile_image_url="http://a0.twimg.com/profile_images/851508584/bio_mtjones_normal.JPG" profile_image_url_https="..." profile_link_color="2FC2EF" profile_sidebar_border_color="181A1E" profile_sidebar_fill_color="252429" profile_text_color="666666" profile_use_background_image=true protected=false screen_name="MTimJones" show_all_inline_media=false status=<#Hashie::Mash contributors=nil coordinates=nil created_at="Sat Jul 02 02:03:24 +0000 2011" favorited=false geo=nil id=86978247602094080 id_str="86978247602094080" in_reply_to_screen_name="AnonymousIRC" in_reply_to_status_id=nil in_reply_to_status_id_str=nil in_reply_to_user_id=225663702 in_reply_to_user_id_str="225663702" place=<#Hashie::Mash attributes=<#Hashie::Mash> bounding_box=<#Hashie::Mash coordinates=[[[-105.178387, 40.12596], [-105.034397, 40.12596], [-105.034397, 40.203495], [-105.178387, 40.203495]]] type="Polygon" > country="United States" country_code="US" full_name="Longmont, CO" id="2736a5db074e8201" name="Longmont" place_type="city" url="http://api.twitter.com/1/geo/id/2736a5db074e8201.json" > retweet_count=0 retweeted=false source="web" text="@AnonymousIRC @anonymouSabu @LulzSec @atopiary @Anonakomis Practical reading for future reference... LULZ \"Prison 101\" http://t.co/sf8jIH9" truncated=false > statuses_count=79 time_zone="Mountain Time (US & Canada)" url="http://www.mtjones.com" utc_offset=-25200 verified=false > => nil irb(main):008:0>
这就是快速展示部分的内容。现在,我们来研究一些简单的脚本,你可以在这些脚本中使用Ruby和Twitter API来收集和可视化数据。在这一过程中,你会了解到Twitter的一些概念,比如说身份验证和频率限制等。
挖掘Twitter数据
接下来的几节内容介绍几个通过Twitter API来收集和呈现可用数据的脚本,这些脚本重点在于其简易性,不过你可以通过扩展以及组合他们来创建新的功能。另外,本节内容还会提到Twitter gem API,这一API中有着更多可用的功能。
需要注意的很重要的一点是,在指定的时间内,Twitter API只允许客户做有限次的调用,这也就是Twitter的频率限制请求(现在是一小时不超过150次),这意味着经过某个次数的使用后,你会收到一个错误消息,并要求你在提交新的请求之前先做一段时间的等待。
用户信息
回想一下清单2中的每个Twitter用户的大量可用信息,只有在用户不受保护的情况下这些信息才是可访问的。我们来看一下如何以一种更便捷的方式来提取用户的信息并呈现出来。
清单3给出了一个(基于用户的界面显示名称)检索用户信息的简单的Ruby脚本,然后显示一些更有用的内容,在需要时使用Ruby方法to_s来把值转换成字符串。需要注意的是,首先用户是不受保护的,否则的话是不能访问到她/他的数据的。
清单3. 提取Twitter用户数据的简单脚本(user.rb)
#!/usr/bin/env ruby require "rubygems" require "twitter" screen_name = String.new ARGV[0] a_user = Twitter.user(screen_name) if a_user.protected != true puts "Username : " + a_user.screen_name.to_s puts "Name : " + a_user.name puts "Id : " + a_user.id_str puts "Location : " + a_user.location puts "User since : " + a_user.created_at.to_s puts "Bio : " + a_user.description.to_s puts "Followers : " + a_user.followers_count.to_s puts "Friends : " + a_user.friends_count.to_s puts "Listed Cnt : " + a_user.listed_count.to_s puts "Tweet Cnt : " + a_user.statuses_count.to_s puts "Geocoded : " + a_user.geo_enabled.to_s puts "Language : " + a_user.lang puts "URL : " + a_user.url.to_s puts "Time Zone : " + a_user.time_zone puts "Verified : " + a_user.verified.to_s puts tweet = Twitter.user_timeline(screen_name).first puts "Tweet time : " + tweet.created_at puts "Tweet ID : " + tweet.id.to_s puts "Tweet text : " + tweet.text end
若要调用这一脚本,需要确保其是可执行的(chmod +x user.rb),使用一个用户的名称来调用它。清单4显示了使用用户developerworks调用的结果,给出了用户的信息和当前状态(最后一条tweet消息)。这里要注意的是,Twitter把关注你的人定义为followers(粉丝);而把你关注的人称作friends(朋友)。
清单4. user.rb的输出例子
$ ./user.rb developerworks Username : developerworks Name : developerworks Id : 16362921 Location : User since : Fri Sep 19 13:10:39 +0000 2008 Bio : IBM's premier Web site for Java, Android, Linux, Open Source, PHP, Social, Cloud Computing, Google, jQuery, and Web developer educational resources Followers : 48439 Friends : 46299 Listed Cnt : 3801 Tweet Cnt : 9831 Geocoded : false Language : en URL : http://bit.ly/EQ7te Time Zone : Pacific Time (US & Canada) Verified : false Tweet time : Sun Jul 17 01:04:46 +0000 2011 Tweet ID : 92399309022167040 Tweet text : dW Twitter is saving #IBM over $600K per month: will #Google+ add to that? > http://t.co/HiRwir7 #Tech #webdesign #Socialmedia #webapp #app
朋友的受欢迎情况
研究一下你的朋友(你关注的人),收集数据来了解一下他们的受欢迎程度。在这个例子中,收集朋友的数据并按照他们的粉丝数目来进行排序,这一简单的脚本如清单5所示。
在这一脚本中,在了解了你要(基于界面显示名称)分析的用户后,创建一个用户哈希表,Ruby哈希(或是相关的数组)是一种可以允许你定义存储键(而不是简单的数值索引)的数据结构。接着,通过Twitter的界面名称来索引这一哈希表,关联值则是用户的粉丝数目。这一过程简单地遍历你的朋友然后把他们的粉丝的数目放入哈希表中,接着(以降序)排列哈希表,然后把它放到输出中。
清单5. 关于朋友的受欢迎程度的脚本(friends.rb)
#!/usr/bin/env ruby require "rubygems" require "twitter" name = String.new ARGV[0] user = Hash.new # Iterate friends, hash their followers Twitter.friends(name).users.each do |f| # Only iterate if we can see their followers if (f.protected.to_s != "true") user[f.screen_name.to_s] = f.followers_count end end user.sort_by {|k,v| -v}.each { |user, count| puts "#{user}, #{count}" }
清单5中的朋友脚本的一个例子输出如清单6所示。我删减了输出内容以节省空间,不过你可以看到,在我的直接网络中,ReadWriteWeb(RWW)和Playstation是很受欢迎的Twitter用户。
清单6. 清单5中的朋友脚本的界面输出
$ ./friends.rb MTimJones RWW, 1096862 PlayStation, 1026634 HarvardBiz, 541139 tedtalks, 526886 lifehacker, 146162 wandfc, 121683 AnonymousIRC, 117896 iTunesPodcasts, 82581 adultswim, 76188 forrester, 72945 googleresearch, 66318 Gartner_inc, 57468 developerworks, 48518
我的粉丝来自哪里
回想一下清单2,Twitter提供了丰富的位置信息,有一个不限形式、用户定义的、可选用地理编码数据的位置字段。不过,用户设定的时区也可以为粉丝的实际位置提供线索。
在这一例子中,你要构建一个混搭应用程序来从Twitter粉丝中提取时区数据,然后使用Google Charts来可视化这一数据。Google Charts是一个非常有意思的项目,其允许你通过网络来构建各种各样不同类型的图表;把图表的类型和数据定义成HTTP请求,直接在浏览器中渲染作为响应的结果。若要安装用于Google Charts的Ruby gem,使用下面的命令行:
$ gem install gchartrb
清单7提供的脚本提取时区数据,接着构建Google Charts请求。首先,与之前的脚本不同,这一脚本需要你通过Twitter的身份验证。若要做到这一点,你需要注册一个Twitter应用,这会给你提供一组键值和令牌,这些令牌可以用在清单7的脚本中,这样才能够成功地取到数据。请参阅参考资料了解这一简单过程的详细情况。
按照相类似的模式,该脚本接受了一个界面名称,然后遍历该用户的粉丝,从当前粉丝中提取时区并把它存放在tweetlocation哈希表中。需要注意的是,你先要检测该键值是否已经存在于哈希表中,若是的话,增加该键值的计数。你还可以记住所有时区的个数,以用于后面的百分比的计算。
这一脚本的最后一部分内容是构造Google Pie Chart的URL,创建一个新的PieChart,指定一些选项(大孝标题和是否为3D等);接着,遍历时区哈希表,找出用于图表的时区串的数据(删去&符号)以及该时区计数与总数的百分比。
清单7.通过Twitter的时区来构建一个饼图(followers-location.rb)
#!/usr/bin/env ruby require "rubygems" require "twitter" require 'google_chart' screen_name = String.new ARGV[0] tweetlocation = Hash.new timezones = 0.0 # Authenticate Twitter.configure do |config| config.consumer_key = '' config.consumer_secret = '' config.oauth_token = ' config.oauth_token_secret = '' end # Iterate followers, hash their location followers = Twitter.followers.users.each do |f| loc = f.time_zone.to_s if (loc.length > 0) if tweetlocation.has_key?(loc) tweetlocation[loc] = tweetlocation[loc] + 1 else tweetlocation[loc] = 1 end timezones = timezones + 1.0 end end # Create a pie chart GoogleChart::PieChart.new('650x350', "Time Zones", false ) do |pc| tweetlocation.each do |loc,count| pc.data loc.to_s.delete("&"), (count/timezones*100).round end puts pc.to_url end
若要执行清单7中的脚本,给它提供一个Twitter界面显示名称,然后把得出的URL拷贝并粘贴到浏览器中,清单8给出了这一过程及最终生成的URL。
清单8. 调用followers-location脚本(结果只是一行来的)
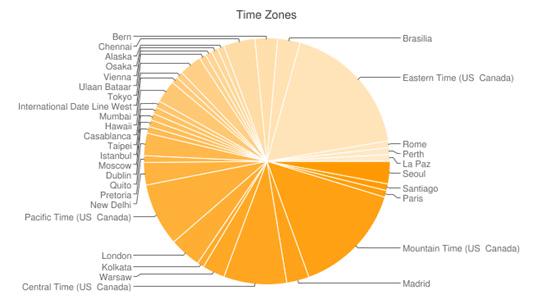
$ ./followers-location.rb MTimJones http://chart.apis.google.com/chart?chl=Seoul|Santiago|Paris|Mountain+Time+(US++Canada)| Madrid|Central+Time+(US++Canada)|Warsaw|Kolkata|London|Pacific+Time+(US++Canada)| New+Delhi|Pretoria|Quito|Dublin|Moscow|Istanbul|Taipei|Casablanca|Hawaii|Mumbai| International+Date+Line+West|Tokyo|Ulaan+Bataar|Vienna|Osaka|Alaska|Chennai|Bern| Brasilia|Eastern+Time+(US++Canada)|Rome|Perth|La+Paz &chs=650x350&chtt=Time+Zones&chd=s:KDDyKcKDOcKDKDDDDDKDDKDDDDOKK9DDD&cht=p $
把清单8中的URL粘贴到浏览器中,你就可以得到图1所示的结果。
图1. Twitter粉丝位置分布的饼图
Twitter用户的行为
Twitter包含了大量的数据,你可以通过挖掘这些数据来了解用户行为的某些要素。两个简单例子将用来分析Twitter用户何时发布消息以及通过什么应用来发布消息,你可以使用下面两个简单的脚本来提取并可视化这些信息。
清单9给出的脚本遍历了某个特定用户的tweet消息(使用user_timeline方法),然后从每条tweet消息中提取出该tweet消息形成的具体时间,一个简单的哈希表被再次用来统计一周中每天的计数,然后以与前面的时区例子相类似的方式使用Google Charts生成一个柱状图。
清单9. 构建tweet发布时间的柱状图(tweet-days.rb)
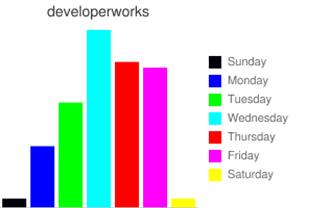
#!/usr/bin/env ruby require "rubygems" require "twitter" require "google_chart" screen_name = String.new ARGV[0] dayhash = Hash.new timeline = Twitter.user_timeline(screen_name, :count => 200 ) timeline.each do |t| tweetday = t.created_at.to_s[0..2] if dayhash.has_key?(tweetday) dayhash[tweetday] = dayhash[tweetday] + 1 else dayhash[tweetday] = 1 end end GoogleChart::BarChart.new('300x200', screen_name, :vertical, false) do |bc| bc.data "Sunday", [dayhash["Sun"]], '00000f' bc.data "Monday", [dayhash["Mon"]], '0000ff' bc.data "Tuesday", [dayhash["Tue"]], '00ff00' bc.data "Wednesday", [dayhash["Wed"]], '00ffff' bc.data "Thursday", [dayhash["Thu"]], 'ff0000' bc.data "Friday", [dayhash["Fri"]], 'ff00ff' bc.data "Saturday", [dayhash["Sat"]], 'ffff00' puts bc.to_url end
图2提供了使用developerWorks帐户来执行清单9中的tweet-days脚本的结果,正如所展示的那样,星期三是发布tweet消息最活跃的一条,最不活跃的是星期六和星期天。
图2. 比较每天的tweet活跃程度的柱状图
接下来的脚本确定特定用户通过哪一个来源发布tweet消息,你可以通过几种方式来发布消息,这一脚本并未对每一种都做了编码。如清单10所示,使用类似的模式来提取给定用户的时间轴上的内容,然后尝试着解码哈希表中的tweet消息的发出处。稍后这一哈希表会被用来创建一个简单的饼图,使用Google Charts来可视化数据。
清单10. 构建用户的tweet消息源的饼图(tweet-source.rb)
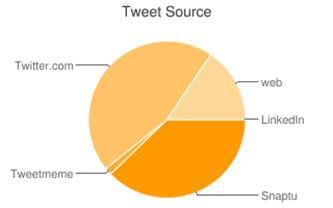
#!/usr/bin/env ruby require "rubygems" require "twitter" require 'google_chart' screen_name = String.new ARGV[0] tweetsource = Hash.new timeline = Twitter.user_timeline(screen_name, :count => 200 ) timeline.each do |t| if (t.source.rindex('blackberry')) then src = 'Blackberry' elsif (t.source.rindex('snaptu')) then src = 'Snaptu' elsif (t.source.rindex('tweetmeme')) then src = 'Tweetmeme' elsif (t.source.rindex('android')) then src = 'Android' elsif (t.source.rindex('LinkedIn')) then src = 'LinkedIn' elsif (t.source.rindex('twitterfeed')) then src = 'Twitterfeed' elsif (t.source.rindex('twitter.com')) then src = 'Twitter.com' else src = t.source end if tweetsource.has_key?(src) tweetsource[src] = tweetsource[src] + 1 else tweetsource[src] = 1 end end GoogleChart::PieChart.new('320x200', "Tweet Source", false) do |pc| tweetsource.each do|source,count| pc.data source.to_s, count end puts "\nPie Chart" puts pc.to_url end
图3提供了一个可视化图表,显示了一组Twitter用户感兴趣使用的tweet消息发布源,传统的Twitter网站最常用到,随后是移动电话应用。
图3. Twitter用户的tweet消息发布源的饼图
反映粉丝情况的图表
Twitter是一个庞大的用户网络,这些用户形成了一个网络图。正如你通过脚本所看到的那样,遍历你的联系人很容易,接着遍历他们的联系人也很容易。即使只是在这一级别上,这样做也已建立起一张大图的基本面。
为了可视化图形,我选择使用图形可视化软件GraphViz。在Ubuntu上,使用下面的命令行,你可以很容易就安装好这一工具:
$ sudo apt-get install graphviz
清单11中的脚本遍历了用户的粉丝,然后再遍历这些粉丝他们的粉丝。这一模式中的唯一真正不同之处在于 GraphViz的DOT格式文件的构造,GraphViz使用简单的脚本格式来定义图形,这些图形作为你列举的Twitter用户的组成部分出现。如清单所展示的那样,可以简单地通过指定节点的关系来定义图形。
清单11. 可视化Twitter粉丝图(followers-graph.rb)
#!/usr/bin/env ruby require "rubygems" require "twitter" require 'google_chart' screen_name = String.new ARGV[0] tweetlocation = Hash.new # Authenticate Twitter.configure do |config| config.consumer_key = '' config.consumer_secret = '' config.oauth_token = '' config.oauth_token_secret = '' end my_file = File.new("graph.dot", "w") my_file.puts "graph followers {" my_file.puts " node [ fontname=Arial, fontsize=6 ];" # Iterate followers, hash their location followers = Twitter.followers(screen_name, :count=>10 ).users.each do |f| # Only iterate if we can see their followers if (f.protected.to_s != "true") my_file.puts " \"" + screen_name + "\" -- \"" + f.screen_name.to_s + "\"" followers2 = Twitter.followers(f.screen_name, :count =>10 ).users.each do |f2| my_file.puts " \"" + f.screen_name.to_s + "\" -- \"" + f2.screen_name.to_s + "\"" end end end my_file.puts "}"
在某个用户上执行清单11的脚本,得出的结果放在一个dot文件中,接着使用GraphViz来生成图像。首先调用Ruby脚本来收集图形数据(存储成graph.dot);接着使用GraphViz来生成图像(这里用的是circo,该工具指定了一种圆形的布局)。生成图像的过程定义如下:
$ ./followers-graph.rb MTimJones $ circo graph.dot -Tpng -o graph.png
最终得出的图像如图4所示。需要注意的是,由于这一Twitter图表可能会很大,因为我们通过尽量减少要列举的用户及其粉丝的数目来限制图表的规模(通过清单11中的:count选项)。
图4. Twitter粉丝图例子(极端情况的子集)

位置信息
在功能启用的情况下,Twitter收集你和你发出tweet消息的地理位置数据。这些由经度和纬度信息组成的数据能够用来精确地定位用户的位置或者是tweet消息从何处发出。此外,把搜索和这些消息结合在一起,你就可以根据已定义的位置或是你所处的位置来识别出某些地方或是某些人。
并非所有的用户或是tweet消息都启用了地理位置功能(出于隐私原因),但这一信息是所有Twitter体验当中的一个非常吸引人的方面。让我们来看一个脚本,该脚本允许你可视化地理定位数据,还有另一个脚本允许你使用这一数据来进行搜索。
第一个脚本(清单12所示)抓取用户的经度和纬度数据(回想一下清单2中的边界框(bounding box)),尽管边界框是一个定义代表了用户区域的多边形,但我做了简化,只用了这一区域中的一个点。有了这一数据,我在一个简单的HMTL文件中生成了一个简单的JavaScript函数,这一JavaScript代码与Google Maps接口,给出了这一位置的一个俯视地图(给出提取自Twitter用户的经度和纬度数据)。
清单12. 构造用户地图的Ruby脚本(where-am-i.rb)
#!/usr/bin/env ruby require "rubygems" require "twitter" Twitter.configure do |config| config.consumer_key = '<consumer_key> config.consumer_secret = '<consumer_secret> config.oauth_token = '<oauth_token> config.oauth_token_secret = '<token_secret> end screen_name = String.new ARGV[0] a_user = Twitter.user(screen_name) if a_user.geo_enabled == true long = a_user.status.place.bounding_box.coordinates[0][0][0]; lat = a_user.status.place.bounding_box.coordinates[0][0][1]; my_file = File.new("test.html", "w") my_file.puts "<!DOCTYPE html> my_file.puts "<html>< head> my_file.puts "<meta name=\"viewport\" content=\"initial-scale=1.0, user-scalable=no\"/>" my_file.puts "<style type=\"text/css\">" my_file.puts "html { height: 100% }" my_file.puts "body { height: 100%; margin: 0px; padding: 0px }" my_file.puts "#map_canvas { height: 100% }" my_file.puts "</style>" my_file.puts "< script type=\"text/javascript\"" my_file.puts "src=\"http://maps.google.com/maps/api/js?sensor=false\">" my_file.puts "</script>" my_file.puts "<script type=\"text/javascript\">" my_file.puts "function initialize() {" my_file.puts "var latlng = new google.maps.LatLng(" + lat.to_s + ", " + long.to_s + ");" my_file.puts "var myOptions = {" my_file.puts "zoom: 12," my_file.puts "center: latlng," my_file.puts "mapTypeId: google.maps.MapTypeId.HYBRID" my_file.puts "};" my_file.puts "var map = new google.maps.Map(document.getElementById(\"map_canvas\")," my_file.puts "myOptions);" my_file.puts "}" my_file.puts "</script>" my_file.puts "</head>" my_file.puts "<body onload=\"initialize()\">" my_file.puts "<div id=\"map_canvas\" style=\"width:100%; height:100%\"></div>" my_file.puts "</body>" my_file.puts "</html>" else puts "no geolocation data available." end
清单12中的脚本执行起来很简单:
$ ./where-am-i.rb MTimJones
最终得出的HTML文件可以通过浏览器来渲染,像这样:
$ firefox test.html
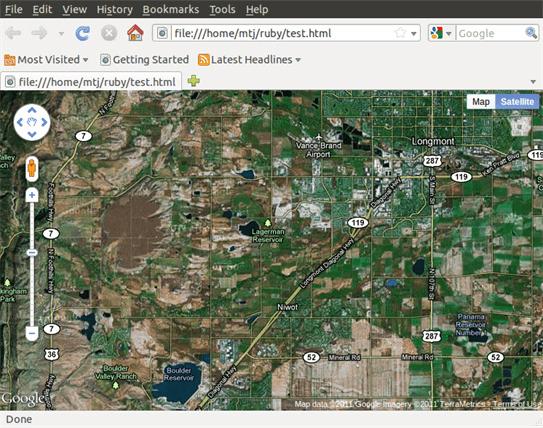
如果没有可用的位置信息的话,这一脚本就会执行失败;不过如果执行成功的话,就会生成一个HTML文件,浏览器可以读入该文件来渲染出地图。图5给出了最终生成的地图图像,其显示了美国科罗拉多州北部Front Range的部分地区。
图5. 清单12中的脚本渲染图像的例子
有了地理位置,你还可以通过搜Twitter来识别出与某个特定位置相关联的Twitter用户和tweet消息。Twitter搜索API允许使用地理编码信息来限定搜索结果。下面清单13中的例子提取用户的经度和纬度,然后使用这些数据获取该位置方圆5公里之内的所有tweet消息。
清单13. 使用经度和纬度数据来搜索局部地区的tweet消息(tweets-local.rb)
#!/usr/bin/env ruby require "rubygems" require "twitter" Twitter.configure do |config| config.consumer_key = '' config.consumer_secret = '' config.oauth_token = '' config.oauth_token_secret = '' end screen_name = String.new ARGV[0] a_user = Twitter.user(screen_name) if a_user.geo_enabled == true long = a_user.status.place.bounding_box.coordinates[0][0][0] lat = a_user.status.place.bounding_box.coordinates[0][0][1] Array tweets = Twitter::Search.new.geocode(lat, long, "5mi").fetch tweets.each do |t| puts t.from_user + " | " + t.text end end
清单13中的脚本的执行结果显示在清单14中,这是指定位置范围内的Twitter用户发布的tweet消息的一个子集。
清单14. 查询我所在位置方圆5公里之内的这一局部地区的tweet消息。
$ ./tweets-local.rb MTimJones Breesesummer | @DaltonOls did he answer u LongmontRadMon | 60 CPM, 0.4872 uSv/h, 0.6368 uSv/h, 2 time(s) over natural radiation graelston | on every street there is a memory; a time and place we can never be again. Breesesummer | #I'minafight with @DaltonOls to see who will marry @TheCodySimpson I will marry him!!! :/ _JennieJune_ | ok I'm done, goodnight everyone! Breesesummer | @DaltonOls same _JennieJune_ | @sylquejr sleep well! Breesesummer | @DaltonOls ok let's see what he says LongmontRadMon | 90 CPM, 0.7308 uSv/h, 0.7864 uSv/h, 2 time(s) over natural radiation Breesesummer | @TheCodySimpson would u marry me or @DaltonOls natcapsolutions | RT hlovins: The scientific rebuttal to the silly Forbes release this morning: Misdiagnosis of Surface Temperatu... http://bit.ly/nRpLJl $
继续深入
本文给出了一些简单的脚本,这些脚本使用Ruby语言来从Twitter中提取数据,文章的重点放在用来说明一些基本概念的脚本的开发和演示方面,但我们能做的远不止于此。例如,你还可以使用API来浏览你的朋友的网络,并找出你感兴趣的最受欢迎的Twitter用户。另一个吸引人的方面是对tweet消息本身进行挖掘,使用地理位置数据来了解基于位置的行为或是事件(比如说流感暴发)。本文只是做了一个浅显的介绍,请在下面随意发表你的评论,附上你自己的各种混搭程序。Ruby和Twitter gem把为数据挖掘需要开发有用的混搭应用程序和仪表盘工具的工作变得很容易。