如何优化String.ToCharArray内存?
先看下Reflector.exe反汇编.net framework 2.0中Mscorlid.dll,得到String.ToCharArray()源码: //.netframework2.0publicunsafechar[]ToCharArray()
//.netframework2.0publicunsafechar[]ToCharArray()
 {
{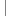 intnum1=this.Length;char[]chArray1=newchar[num1];if(num1>0)
intnum1=this.Length;char[]chArray1=newchar[num1];if(num1>0)
 {fixed(char*chRef1=&this.m_firstChar){//使用fixed,防止gc执行垃圾回收后移动堆上的对象而造成无效指针fixed(char*chRef2=chArray1){string.wstrcpyPtrAligned(chRef2,chRef1,num1);chRef1=null;
{fixed(char*chRef1=&this.m_firstChar){//使用fixed,防止gc执行垃圾回收后移动堆上的对象而造成无效指针fixed(char*chRef2=chArray1){string.wstrcpyPtrAligned(chRef2,chRef1,num1);chRef1=null; }}}returnchArray1;
}}}returnchArray1; }privatestaticunsafevoidwstrcpyPtrAligned(char*dmem,char*smem,intcharCount){while(charCount>=8)//四重展开{*((int*)dmem)=*((uint*)smem);//拷贝32bit*((int*)(dmem+2))=*((uint*)(smem+2));*((int*)(dmem+4))=*((uint*)(smem+4));*((int*)(dmem+6))=*((uint*)(smem+6));dmem+=8;smem+=8;charCount-=8;}if((charCount&4)!=0){*((int*)dmem)=*((uint*)smem);*((int*)(dmem+2))=*((uint*)(smem+2));dmem+=4;smem+=4;}if((charCount&2)!=0){*((int*)dmem)=*((uint*)smem);dmem+=2;smem+=2;}if((charCount&1)!=0){dmem[0]=smem[0];}}
}privatestaticunsafevoidwstrcpyPtrAligned(char*dmem,char*smem,intcharCount){while(charCount>=8)//四重展开{*((int*)dmem)=*((uint*)smem);//拷贝32bit*((int*)(dmem+2))=*((uint*)(smem+2));*((int*)(dmem+4))=*((uint*)(smem+4));*((int*)(dmem+6))=*((uint*)(smem+6));dmem+=8;smem+=8;charCount-=8;}if((charCount&4)!=0){*((int*)dmem)=*((uint*)smem);*((int*)(dmem+2))=*((uint*)(smem+2));dmem+=4;smem+=4;}if((charCount&2)!=0){*((int*)dmem)=*((uint*)smem);dmem+=2;smem+=2;}if((charCount&1)!=0){dmem[0]=smem[0];}}
ToCharArray中使用了fixed来防止gc执行垃圾回收后移动托管堆上的对象。托管堆的工作方式类似于栈,在某种程度上,连续的对象会在内存紧挨的位置放置,这样很容易使用指向下一个空闲存储单元的堆指针,来确定下一个对象的位置。在gc回收不再引用的对象所占用的内存后,现存对象在内存的位置可能不再连续,此时gc会把所有对象移动到托管堆的端部,在次形成一个连续的块。当然,在移动对象时,这些对象的所有引用都需要用正确的新地址来更新。gc的这个压缩操作时托管的堆与非托管堆的区别所在。使用托管堆,就只需要读取堆指针的值即可,而不是搜索链接地址列表,来查找一个地方放置新对象。因此在.net下实例化对象要快得多。
使用了fixed后,在fixed块语句内指针所指向的对象将不会在托管堆上移动,从而保证wstrcpyPtrAligned方法中的指正都指向正确的内存地址。
wstrcpyPtrAligned方法中也用几点内存优化技巧(《代码优化规则》摘录了更多的技巧):
1. *((int*) targetAddress) = *((uint*) originalAddress);
将执行char的指针转换成指向int/uint的指针,从而实现每次读取32bit的数据。
2. while (charCount >= 8){}
按四重展开循环。流水线型CPU对分支语句表现出过度敏感,从而降低了分支语句的执行速度(循环语句也是一种分支语句)。可以把CPU比作赛跑选手,把代码比作跑道,选手会在每个弯道(分支语句)处减速。循环展开有助于减少分支,从而减少运行时间。一般按4/8/16重展开,再继续展开的话,优化效果可以忽略,而书写的代码量大,CPU的Cache也容不下这个庞然大物。--《代码优化:有效使用内存》
3.*((int*) dmem) = *((uint*) smem);
*((int*) (dmem + 2)) = *((uint*) (smem + 2));
*((int*) (dmem + 4)) = *((uint*) (smem + 4));
*((int*) (dmem + 6)) = *((uint*) (smem + 6));
dmem += 8;
smem += 8;
前面四条语句都是根据dmen/smen+X来定位地址,消除了语句之间的数据相关性。如果写成下面这样:
*((int*) dmem) = *((uint*) smem);
dmem += 2; smem += 2;
*((int*) dmem) = *((uint*) smem);
dmem += 2; smem += 2;
*((int*) dmem) = *((uint*) smem);
dmem += 2; smem += 2;
*((int*) dmem) = *((uint*) smem);
dmem += 2; smem += 2;
这种写法不但增加了代码量,而且还降低了指令执行的并发度。
另外,.net framework 1.1中的ToCharArray()的实现与2.0版本中的有所不同,下面是ToCharArray方法的源码:
//.netframework1.1publicchar[]ToCharArray(){returnthis.ToCharArray(0,this.Length);}publicchar[]ToCharArray(intstartIndex,intlength){if(((startIndex<0)||(startIndex>this.Length))||(startIndex>(this.Length-length))){thrownewArgumentOutOfRangeException("startIndex",Environment.GetResourceString("ArgumentOutOfRange_Index"));}if(length<0){thrownewArgumentOutOfRangeException("length",Environment.GetResourceString("ArgumentOutOfRange_Index"));}char[]chArray1=newchar[length];this.InternalCopyTo(startIndex,chArray1,0,length);returnchArray1;}[MethodImpl(MethodImplOptions.InternalCall)]internalexternvoidInternalCopyTo(intsourceIndex,char[]destination,intdestinationIndex,intcount);本文地址:http://www.45fan.com/a/question/68482.html