如何通过python实现爬虫数据存到MongoDB?
在以上两篇文章中已经介绍到了 Python 爬虫和 MongoDB , 那么下面我就将爬虫爬下来的数据存到 MongoDB 中去,首先来介绍一下我们将要爬取的网站, readfree 网站,这个网站非常的好,我们只需要每天签到就可以免费下载三本书,良心网站,下面我就将该网站上的每日推荐书籍爬下来。
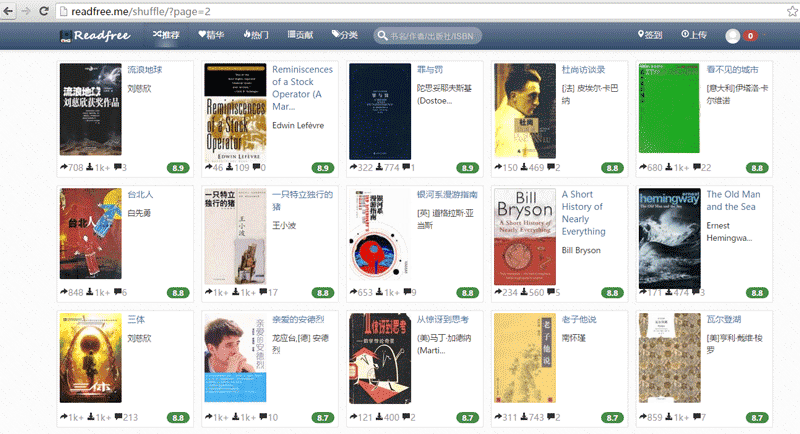
利用上面几篇文章介绍的方法,我们很容易的就可以在网页的源代码中寻找到书籍的姓名和书籍作者的信息。
找到之后我们复制 XPath ,然后进行提取即可。源代码如下所示
# coding=utf-8 import re import requests from lxml import etree import pymongo import sys reload(sys) sys.setdefaultencoding('utf-8') def getpages(url, total): nowpage = int(re.search('(\d+)', url, re.S).group(1)) urls = [] for i in range(nowpage, total + 1): link = re.sub('(\d+)', '%s' % i, url, re.S) urls.append(link) return urls def spider(url): html = requests.get(url) selector = etree.HTML(html.text) book_name = selector.xpath('//*[@id="container"]/ul/li//div/div[2]/a/text()') book_author = selector.xpath('//*[@id="container"]/ul/li//div/div[2]/div/a/text()') saveinfo(book_name, book_author) def saveinfo(book_name, book_author): connection = pymongo.MongoClient() BookDB = connection.BookDB BookTable = BookDB.books length = len(book_name) for i in range(0, length): books = {} books['name'] = str(book_name[i]).replace('\n','') books['author'] = str(book_author[i]).replace('\n','') BookTable.insert_one(books) if __name__ == '__main__': url = 'http://readfree.me/shuffle/?page=1' urls = getpages(url,3) for each in urls: spider(each)
注意,在写入数据库的过程中不要一下子将字典中的数据写入数据库,我一开始就这么写的,但是我发现数据库中只有三条信息,其他信息都不见了。所以采用一条一条的写入。
还有源代码的开头部分,对默认编码的设置一定不可以省略,否则可能会报编码错误(真心感觉 Python 在编码这方面好容易出错,尴尬)。
有的人可能发现了,我将提取的信息转换成了字符串,然后使用 replace() 方法将 \n 去掉了,因为我发现在提取的书籍信息前后存在换行符,看着十分碍眼。
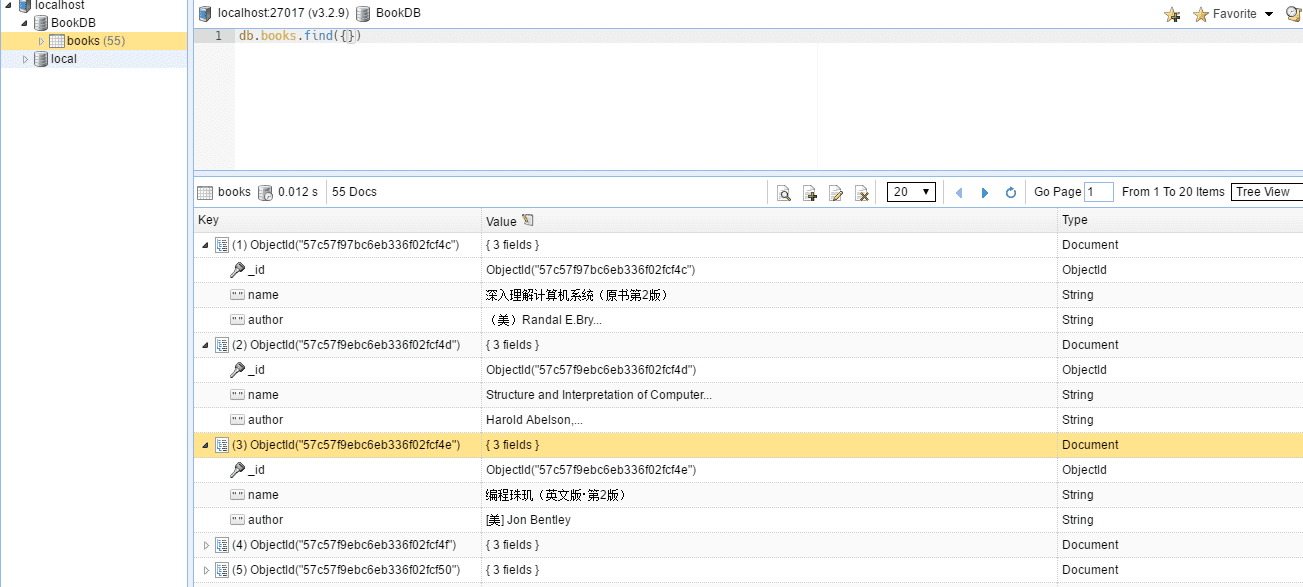
热情提醒一下,在程序运行的时候别忘记将你的 Mongo DB 运行起来,下来看看结果
好了,就这样,如果发现代码哪里存在错误或者说有可以改善的地方,希望留言给我,感谢。