python基于xml格式的日志文件的方法
大家中午好,由于过年一直还没回到状态,好久没分享一波小知识了,今天,继续给大家分享一波Python解析日志的小脚本。
首先,同样的先看看日志是个啥样。

都是xml格式的,是不是看着就头晕了??没事,我们先来分析一波。
1.每一段开头都是catalina-exec,那么我们就按catalina-exec来分,分了之后,他们就都是一段一段的了。
2.然后,我们再在已经分好的一段段里面分,找出你要分割的关键字,因为是xml的,所以,接下来的工作就简单了,都是一个头一个尾的。
3.但是还有一个问题,有可能有的里面没有你想要的关键字,所以你要判断下,如果没有这个字段,那么我就把这个字段设置为空。
思路清晰了,代码自然而然就简单了。
接下来我们就看看代码
#coding:utf-8
import re
#文本所在TXT文件
file = 'iag_interface.log'
#分割一段
xml1='catalina-exec'
xml2='catalina-exec'
#关键字reqtimestamp
time1 = '<timestamp>'
time2 = '</timestamp>'
#关键字functionid
functionid1 = '<functionid>'
functionid2 = '</functionid>'
#关键字transid
transid1='<transid>'
transid2='</transid>'
#关键字siappid
siappid1='<siappid>'
siappid2='</siappid>'
#关键字userid
userid1='<userid>'
userid2='</userid>'
#关键字mobnum
mobnum1='<mobnum>'
mobnum2='</mobnum>'
f = open(file,'r',encoding= 'utf-8')
#f = open(file,'r')
#for (num,value) in enumerate(f):
#print("line number",num,"is:",value)
buff = f.read()
#清除换行符,请取消下一行注释
#buff = buff.replace('\n','')
pat = re.compile(time1+'(.*?)'+time2,re.S)
pat1 = re.compile(functionid1+'(.*?)'+functionid2,re.S)
pat2 = re.compile(transid1+'(.*?)'+transid2,re.S)
pat3 = re.compile(siappid1+'(.*?)'+siappid2,re.S)
pat4 = re.compile(userid1+'(.*?)'+userid2,re.S)
pat5 = re.compile(mobnum1+'(.*?)'+mobnum2,re.S)
pat6=re.compile(xml1+'(.*?)'+xml2,re.S)
result6 = pat6.findall(buff)
print(len(result6))
x = open("logfx.txt", 'w')
x.write("===========================开始数据================================="+"\n")
x.write("time"+"\t"+"functionid"+"\t"+"transid"+"\t"+"siappid"+"\t"+"userid"+"\t"+"mobnum"+"\n")
for i in range(0,len(result6)):
result = pat.findall(result6[i])
result1 = pat1.findall(result6[i])
result2 = pat2.findall(result6[i])
result3 = pat3.findall(result6[i])
result4 = pat4.findall(result6[i])
result5 = pat5.findall(result6[i])
if len(result)==0:
result.append("空")
if len(result1)==0:
result1.append("空")
if len(result2)==0:
result2.append("空")
if len(result3)==0:
result3.append("空")
if len(result4)==0:
result4.append("空")
if len(result5)==0:
result5.append("空")
#print(result[0],"=",result1[0],"=",result2[0],"=",result3[0],"=",result4[0],"=",result5[0])
x.write("timestamp:"+result[0]+"\t"+result1[0]+"\t"+result2[0]+"\t"+result3[0]+"\t"+result4[0]+"\t"+"mobnum:"+result5[0]+"\n")
x.write("===========================结束数据================================="+"\n")
print("执行完毕!生成文件logfx.txt")
x.close()
运行下代码
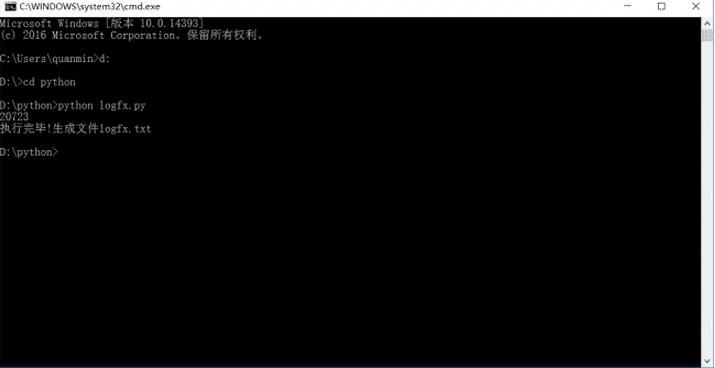
python解析基于xml格式的日志文件把所有数据运行成功了。接下来查看文件
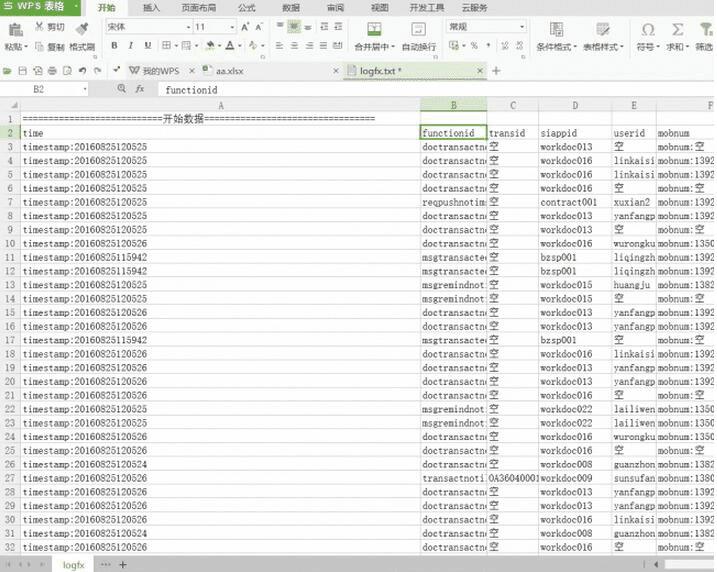
好了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持路饭。
本文地址:http://www.45fan.com/a/question/89038.html