redis
redis特性
1>速度快:redis所有数据都是存放在内存中,是redis速度快的主要原因,是有c编写,一般来说用c编写的程序距离操作系统近,执行速度更快,非阻塞I/O,使用epoll作为I/O多路复用的技术实现,不再网路I/O上浪费过多时间,使用单线程架构,预防了多线程可能产生竞争的问题,对于服务端开发来说,锁和线程切换通常是性能杀手(但是单线程有一个问题就是每个命令执行时间有要求,如果某个命令执行过程,会造成其他命令阻塞,所以redis是面向快速执行场景的数据库)
2>功能丰富,除了五中数据结构,还提供许多额外功能,键过期功能实现缓存,提供发布订阅实现消息系统,支持lua脚本创造新的redis命令,提供了简单事务,提供了流水线功能,这样客户端可以将一批命令一次性传到redis,减少了网络开销
3>简单稳定 redis使用单线程模型,使得服务端处理模型简单,客户端开发变得简单,redis不需要依赖操作系统的类库,(例如Memcache需要依赖libevent这样系统类库),redis自己实现了事件库里功能
4>redis提供了两种持久化方式:RDB和AOF可以把内存的数据保存到硬盘中
5>提供了主从复制
6>提供了sentinel实现高可用,保证节点的故障发现和自动专一,提供了分布式实现cluster,提供了高可用、读写和容量的扩展性
单线程架构:redis使用单线程和I/O多路复用模型实现高性能内存数据库
redis单线程处理命令,一条命令从客户端达到服务端不会立刻执行,所有命令进入一个队列,然后逐个执行,不会产生并发问题
API理解和使用:
string:
set/mset key value mget/get key
keys* 将所有键输出
dbsize 返回键总数
dbsize直接获取redis键总数变量,时间复杂度O1,keys遍历所有键,时间复杂度On
exists key 判断键是否存在
del key [key1,key2]删除
expire key seconds 添加过期时间 ttl查询过期时间 -1没设置过期时间 -2不存在
type key 键类型 object encoding key 返回内部编码
incr/decr key 计数+/- incrby/decrby 自增/减指定数字
如果没有mget要执行n次get
n*get=n*网络时间+n*命令时间 优化为 n*get=1*网络时间+n次命令
append / strlen /getset 设新返旧 / setrange key offeset value
内部编码:int 8长整型/embstr <=39字符串/raw >39字符串
应用场景:共享Session、验证一分钟不超过多少次登陆/限制一个IP不能一分钟之内访问多少次
Hash:
键值本身又是一个键值对结构
hset key field value /hmset user:1 name1 value1 name2 value2
hget key field /hmget key filed1 filed2
hdel key field
hlen key 计算field个数
hexists key field 判断field是否存在
hkeys key 获取所有field /hvals key 获取全部value
hgetall key 获取全部field-value 如果个数比较多,会阻塞redis,可以使用hscan,该命令会渐进式遍历哈希类型
hstrlen key field 计算value的字符串长度
内部编码:
压缩列表(ziplist):当哈希类型元素个数小于配置hash-max-ziplist-entries(默认512个)。同时所有值都小于hash-max-ziplist-value(默认64字节),redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个原色的连续存储,在节省内存比hashtable更优秀
哈希表(hashtable):无法满足ziplist条件会使用,因为此时ziplist的读写效率下降,而hashtable读写时间复杂度为O1,当field个数超过512也会变
应用场景:
可以把关系型数据表记录的用户信息,用户的属性为列,用户信息为用哈希类型存储
区别:
哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型每个键都可以有不同的field,而关系型数据库一旦添加新的列,所有列都要为其设置值。关系式数据库可以做复杂的关系查询,而redis去模拟复杂查询开发困难,维护成本高
三种缓存用户信息的方法:string 和hash
方案一:
set user:1:name tome
set user:1:age 23
优点:简单直观,每个属性都支持更新操作
缺点:占用过多的键,内存占用量大,同时用户信息内存性比较差,一般不会再生产环境使用
方案二:
set user:1 serialize(userInfo)
优点:提高内存使用率
缺点:序列化和反序列化需要开销,每次更新需要进行反序列化,然后在序列化到redis
方案三:
每个用户属性使用一对field-value,只用一个键保存
hmset user:1 name tome age 23 city bj
有点:简单直观,如果合理使用可以减少内存的使用
缺点:要控制ziplist和hashtable两种内部编码的转换,后者消耗更多内存
list:
lrange 0 -1 获取列表全部元素
linsert key before|after b java 某个元素前、后插入元素
llen key
lrem key count value count>0从左到右删除指定value元素 count=0删全部
内部编码:
ziplist(压缩列表):如果元素的个数小于list-max-ziplist-entries(默认512),同时列表中每个元素的值都小于list-max-ziplist-value(默认64字节)。会选用ziplist作为列表的内部实现来减少内存的使用
linkedlist(链表):当列表类型无法满足ziplist条件时候。
使用场景:
1.消息队列:redis的lpush+brpop组合可以实现阻塞队列,多个消费者客户端使用brpop命令阻塞式的抢列表尾部的元素,多个客户端保证消费的负载均衡和高可用性
集合:
一个集合最多存储2的32次方-1元素。redis除了集合内增删改查,同事支持多个集合取交集、并集、差集
sadd key element (O1)
srem key element
scard key 计算元素个数
sismember key elsement 判断元素是否在
srandmember key [count] 随机从集合返回指定个数元素
spop key 从集合随机弹出元素
smembers key 获取所有元素
smembers和range、hgetall都属于比较重的命令,如果元素过多存在阻塞redis的可能性,这个时候使用sscan来完成
集合间的操作:
sinter key.... 求多个集合的交集
suione key.... 求多个集合的并集
sdiff key.... 求多个集合的差集
集合间运算在元素较多的情况下比较耗时,所以redis提供了三个命令(原命令+store)将集合间操作保存在set类型中,比如sinterstore sinter_ s z
内部编码:
intset(整数集合):当集合中元素都是证书个数小于set_max_intset_entries配置(默认512个),redis会选用intset作为集合的内部实现,从而减少内存的使用
hashtable:当集合类型无法满足inset条件时,redis会使用hashtable作为集合的内部实现
使用场景:
比较典型的场景是标签。例如一个电子商务网站对不同标签的用户做不同类型的推荐,当给用户添加标签和给标签添加用户以及删除的时候,防止部分命令造成数据不一致,应该将两个命令放在同一个事务里
sadd=tag 标签
spop/srandmember=Random item 生成随机数 抽奖
sadd+sinter = 社交需求
有序集合:
有序集合中的元素可以排序,但是它和列表使用索引下标作为排序依据不同,它给每个元素设置一个分支score作为排序的依据,有序集合中的元素不能重复,但是score可以重复
命令:
zadd key score member (On)
zcard key 计算成员个数 (O1)
zscore key member 计算成员分数
zrank key member 从低到高 计算成员排名
zrevrank key member 从高到低 计算成员排名
zrem key member 删除成员
zincrby key increment member 增加成员的分数
zrange/zrevrange key start end 返回指定排名范围的成员 [withscores]返回成员的分数
zrangebyscore/zrevrangebyscore key max min 返回指定分数内的成员 [withscores]返回成员的分数
zcount key min max
zremrangebyscore key min max 删除指定分数范围的成员
内部编码:
ziplist:当有序集合的元素个数小于zset-max-ziplist-entries(128个),同时每个元素的值小于zset-max-ziplist-value配置(64字节),redis用ziplist来作为有序集合的内部实现,有效的减少内存
skiplist(跳表):当ziplist不满足,因此此时的ziplist读写效率会下降
使用场景:
排行榜系统
迁移键:
migrate:将dump、restore、del进行组合,具有原子性,在源redis执行即可,数据传输在源redis和目标rdis上完成,目标redis完成restore自己发送ok给源redis,源redis会根据migrate选项是否决定删除
遍历键:keys 和 scan
keys:支持正则匹配的,但是考虑redis是单线程架构就不是特别完美,如果redis产生大量的键,执行keys会造成redis阻塞
scan:有效的解决keys命令存在的问题,采用了渐进式遍历方式,每次scan时间复杂度为O1,但是要实现keys功能,需要执行多次scan
redis存储键值对实际用hashtable的数据结构,每次执行scan,可以想象成只扫描一个字典中一部分键,直到将字典中的所有键遍历完毕
scan cursor [match pattern][count number]遍历的数量默认是10
cursor实际上是一个游标,每次遍历完会返回当前游标的值,直到游标值为0
数据库管理:
切换数据库 select dbIndex
reids 默认配置是有16个数据库,之间的数据没有任何关联,但是已经逐渐弱化这个功能
因为: redis是单线程,如果使用多个数据库,依然使用一个cpu,会受影响,会让调试和运维不同业务数据库变得苦难,加入有一个慢查询,依然会影响其他数据库,定位问题也困难
建议部署多个redis,彼此用端口来区分。这样保证业务之间不收到影响,又合理使用了cpu资源
2.flushab/flushall
前者清除当前数据库,后者清除全部数据库,但是如果键值比较多,会存在阻塞redis可能性
慢查询日志:
只能查询命令执行的时间,不代表客户端没有超时问题
使用config set动态修改:
config set slowlog-log-slower-than 20000 超过了多少微秒
config set slowlog-max-len 1000 记录多少条 config rewrite 持久化到本地配置文件
是一个先进先出的队列
slowlog get [n]
slowlog len
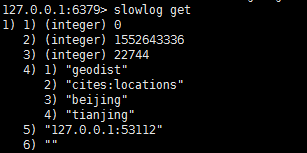
慢查询日志有四个属性组成: 慢查询日志id、发生时间戳、命令耗时、执行命令和参数
注意:慢查询日志只能记录命令执行时间,并不包括排队和网络传输时间,可以定期执行slow get将慢查询日志持久化到mysql中
redis基准性能测试 类似于ab: redis-benchmark -c 并发 -n请求总数 -t 请求方式 get/put --csv
pipeline:(RTT往返时间)
redis提供了批量操作 mget、mset等有效节约RTT,但是大部分命令不支持批量操作
pipeline:能将一组redis命令进行组装,通过一次RTT传输给redis。
pipeline和原生批量命令:
1>原生批量命令是原子的,pipeline是非原子的
2>原生的是一个命令对应多个key,pipeline支持多命令
3>原生的是在redis服务端实现的,而pipeline需要服务端和客户端共同实现
事务与Lua:
事务开启 multi 提交exec 取消:discard
但是redis不支持回滚功能,有些场景需要在事务之前确保事务中的key没有被其他客户端修改过,才能执行事务,负责不执行(类似乐观锁)。redis提供了watch来解决
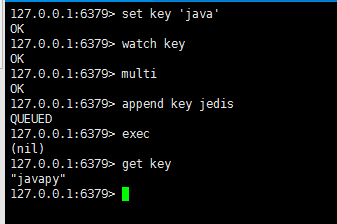
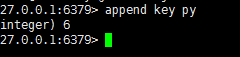
客户端1、2
bitmaps:实现对位的操作
bitmaps不是数据结构,是字符串,但是它可以怼字符串的位进行操作
setbit key offset value
getbit key offset
bitcount key [start][end]
运算:and交集 or 并集 not 非 xor 异或
bitop op destkey key[key] 保存在destkey中
可以用到统计访问网站用户数量: and 几天都访问的,or 任意一天访问的,(月活跃)
Bitmaps分析:
假设网站1亿用户,每天访问5千万对比

但是如果网站访问用户很少,只有10万,很显然bitmap就不太合适了,因为大部分都是0

setbit一个大的偏移量,由于申请大量内存会导致阻塞
HyperLogLog:利用极小内存空间完成独立总数的统计,数据集可以使IP、Email、ID等。
pfadd 、 pfcount、 pfmerge
在进行数据结构选型的时候确认一下几点:
只为了计算独立总数,不获取单条数据
可以容忍一定误差率,比较内存占用量有很大的优势
发布订阅:
publish channel msg 发布
subscribe channel [channel] 订阅
注意:客户端在执行订阅命令之后进入订阅状态,只能接受subscribe、psubscribe、unsubscribe、punsubscribe四个命令,并且新开启订阅的无法收到该频道之前的消息
unsubscribe [channel]取消
pubsub channels [pattern] 查看活跃频道
pubsub numsub 查看频道订阅数
CEO:地理信息定位功能,支持存储地理位置信息用来实现诸如附近位置、摇一摇这类依赖地理位置信息的功能
geoadd key 经度 纬度 成员 更新仍然使用geoadd
geopos key member
geodist key member1 member2 [m/km/mi] 获取两地距离
zrem key member
GEO没有删除成员命令,但是因为GEO底层实现是zset,所以借用zrem实现删除
客户端API
1.client list 能列出与redis服务端相连的所有客户端连接信息

addr:ip和端口
fd:socket文件描述符;fd= -1 不是外部客户端,redis内部伪客户端
nama:客户端名字
qbuf:缓冲区总容量 qbuf-free:剩余容量
redis为每个客户端分配输入缓冲区,作用将客户端发送的命令临时保存,同时redis从会输出缓冲区拉去命令并执行,输入缓冲区为客户端发送命令到redis执行命令提供了缓冲功能,没有提供配置规定缓冲区大小,会根据输入内容不同动态调整,只是要求每个客户端缓冲区的大小不能超过1G
输入缓冲区使用不当产生两个问题:
1>一旦某个客户端的输入缓冲区超过1G,客户端将关闭
2>不受maxmemory控制,假设一个redis设置maxmemory为4G,已经存储2G数据,但是如果此时输入缓冲区使用3G,已经超过maxmemory限制,可能产生数据丢失、键值淘汰、OOM等情况
造成这样的原因:
1>redis处理速度跟不上输入缓冲区输入速度,每次进入输入缓冲区的命令包含了大量bigkey
2>redis发生了阻塞,短期内不能处理命令,造成客户端输入的命令积压在了输入缓冲区里面
解决:定期执行client list 收集qbuf和qbuf-free异常连接记录
通过info clients ,命令中client_recent_max_input_buffer代表最大输入缓冲区古,可以设置超过10M报警
持久化
支持RDB和AOF两种持久化机制,有效避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复
RDB:是把当前进程数据生成快照保存在硬盘的过程,分为手动触发和自动触发
手动触发:save和bgsave
save:阻塞当前redis服务器,直到RDB过程完成为止,对于内存比较大的造成长时间阻塞,线上环境不建议使用
DB saved on disk
bgsave:redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段。
除了执行命令手动触发外,redis内部还存在自动触发RDB持久化机制
1>使用save相关配置,如 save m n (CONFIG get save 、 CONFIG SET SAVE m n) 表示m秒内n次修改时自动触发bgsave
2>如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点。
3>执行debug reload 命令重新加载redis时,也会自动触发save操作
4>默认情况下执行shutdown命令,如果没有开启AOF持久化则自动执行bgsave
流程说明:redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在bgsave命令直接返回,父进程执行fork操作创建子进程,通过info stats查看latest_fork_usec可以获取最近一个fork操作的耗时,单位是微秒,子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换,执行lastsave获取最后一次生成RDB的时间
RDB文件的处理:RDB文件保存在dir配置指定的目录下,可以通过执行config set dir{new dir} 和 config set dbfilename{newFileName}运行期动态执行(当坏盘或者磁盘写完情况下,同样适用于AOF持久化文件)
压缩:redis默认采用LZF算法对生成的RDB文件做压缩处理,config set rdbcompression yes|no 进行修改,如果加载损坏的rdb文件时拒绝启动,可以使用redis提供的redis-check-dump工具检测RDB文件并获取对应错误报告
RDB的优点:
RDB是一个紧凑的二进制文件,代表Redis在某个时间点上的数据,非常适合备份,全量复制等,比如每6小时执行bgsave备份,并把RDB文件拷贝到远程机器用于灾难恢复,加载RDB回复数据远远快于AOF方式
RDB的缺点:
没办法做到实时持久化/秒级持久化,因为bgsave每次运行都要执行fork操作创建子进程,执行成本过高,使用特定二进制保存,redis有多个格式rdb版本,存在老版本redis服务无法兼容新版本rdb格式问题
AOF:以独立日志方式记录每次写命令,重启时再重新执行AOF文件中命令达到恢复数据的目的。
主要作用解决了数据持久化的实时性,目前已经是redis持久化的主流方式
AOF工作流程:命令写入(append)、文件同步(sync)、文件重写(rewrite)、重启加载(load)
所有写入命令追加到aof_buf(缓冲区)中,AOF缓冲根据对应的策略向硬盘做同步操作,随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩目的,当redis服务器重启时,可以加载AOF文件进行数据恢复
命令重写:AOF写入内容直接是文本协议格式(兼容性好、可读性、方便直接修改和处理),写入aof_buf避免每次写入AOF命令直接追加到硬盘,还有好处redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡
文件同步:redis提供了多种AOF缓冲同步文件策略,由appendfsync控制
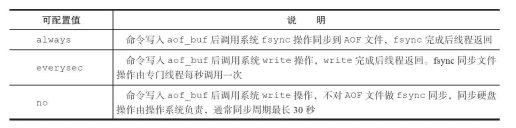
配置always每次写入都要同步AOF,配置no,每次同步AOF周期不可控,会加大每次同步硬盘数据量,虽然提升了性能,但数据安全性无法保证,配置为everysec,做到兼顾性能和数据安全性。理论上只有系统突然宕机情况下丢失1秒数据
wirte:会触发延迟写机制,linux内核提供页缓冲区用来提高硬盘IO性能。write在写入系统缓冲区后直接返回。同步硬盘操作依赖于系统调度机制。例如:缓冲区页空间写满或者达到特定时间周期。同步文件之间,如果此时系统故障宕机,缓冲区内数据将丢失
fsync:针对单个文件操作(比如AOF文件),做强制性硬盘同步,将阻塞写入硬盘完成后返回,保证数据持久化
重写机制:随着命令不断写入AOF,文件越来越大,这个时候redis引入重写机制压缩文件体积
1>进程内已经超时的数据不再写入文件
2>旧的AOF文件含有无效的命令比如del key1、set a 111等。重写使进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令
3>多条命令可以合并为一个,如lpush list a、lpush list b等。
AOF重写可以手动或自动触发
手动:直接调用bgrewriteaof
自动:根据auto-aof-rewite-min-size和auto-aof-rewite-percentage确定自动触发时机
前者表示AOF重写文件最小体积,默认64MB 后者表示当前AOF文件空间和上一次重写AOF文件空间比值
AOF重写内部流程图:
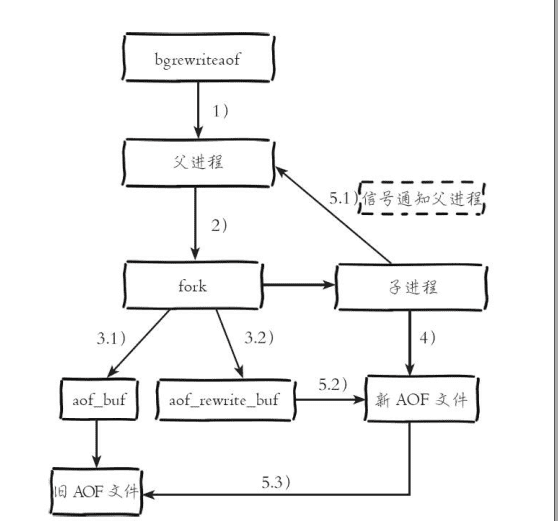
流程说明:执行AOF重写(如果进行bgsave,延迟到bgsave完成之后执行),父进程创建fork创建子进程(开销等同bgsave过程)
3.1 fork操作完成后继续响应其他命令。所有修改命令依然写入AOF缓冲区并根据appendfsync策略同步到磁盘,保证AOF机制正确性
3.2由于fork运用写时复制,子进程只能共享fork操作时的内存数据由于父进程依然响应命令,Redis使用AOF重写缓冲区保存这部分新的数据,防止新的AOF文件生成期间丢失这部分数据
4子进程根据内存快照,按照命令合并规则写入到新的AOF文件。每次批量写入硬盘数据由aof-rewrite-incremental-fsync控制,默认为32MB,防止单次刷盘数据过多造成硬盘阻塞
5.1新的AOF写入,子进程发送信号给父进程,父进程更新统计时间
5.2父进程把AOF重写缓冲区数据写入新的AOF文件
5.3使用新的AOF替换老文件,完成AOF重写
重启加载:
AOF持久化开启且存在AOF文件时,优先加载AOF文件,对于错误格式AOF,采用redis-check-aof-fix进行修复,如果AOF文件存在结尾不完整(突然断电),可以使用aof-load-truncated,忽略并启动,同时打印警告日志
问题定位与优化:
1.fork耗时问题定位:虽然fork创建子进程不需要拷贝父进程的物理内存空间,但是会复制父进程的空间内存页表,因此fork跟进程总内存量息息相关,如果使用虚拟化技术fork操作更耗时
如何改善:
1>优先使用物理机或者高效支持fork操作的虚拟化技术
2>控制redis实例化最大内存,fork耗时跟内存量正比。线上建议每个redis实例内存控制10gb以内
3>合理配置linux内存分配策略,避免物理内存不足导致fork失败
4>降低fork操作的频率
2.子进程开销监控和优化
子进程负责AOF或者RDB文件重写,设计CPU、内存、硬盘的消耗
1>CPU
子进程负责把进程内的数据分批写入文件,这个过程属于CPU密集操作(通常子进程对单核CPU利用率接近90%),redis是CPU密集型服务,不要做绑定单核CPU操作,由于子进程非常消耗CPU,会和父进程产生单核资源竞争。不要和其他CPU密集型服务部署在一起,造成CPU过度竞争,如果部署多个Redis实例,保证同一时刻只有一个子进程执行重写工作
2>内存
子进程通过fork产生,占用内存大小等同于父进程,理论上需要两倍内存来完成持久化操作,但Linux有写时复制机制。父子进程会共享相同的物理内存页,当父进程处理写请求时会把要修改的页创建副本,而子进程在fork操作过程共享整个父进程内存快照
内存消耗监控。
RDB重写时,父进程负责创建所修改内存页的副本,从日志中可以看出这部分内存消耗了5MB,等价于RDB重写消耗
但是AOF重写需要AOF重写缓冲区,所以为53+1.49MB,也就是AOF重写时子进程消耗内存量
避免大量写入时做子进程重写操作,这样将导致父进程维护大量页副本,造成内存消耗
3>硬盘
子进程把AOF或者RDB写入硬盘持久化,造成硬盘写入压力
优化:
a>不要把其他高硬盘副班的服务部署在一起,如:存储、消息队列等
b>AOF重写会消耗大量IO,可以开启配置no-appedfsync-no-rewrite。表示AOF重写期间不做fsync操作(极端情况下可能丢失整个AOF重写期间数据,需要根据数据安全性决定是否配置)
c>当开启AOF的Redis用于高流量写入场景时,如果是普通机械磁盘,写入吞吐量为100MB/s,这个时候Redis实例的瓶颈主要在AOF同步硬盘上
d>对于单机配置多个redis,可以配置不同实例分盘存储AOF文件,分摊写入压力
3.AOF追加阻塞
常用的同步硬盘策略是everysec,用于平衡性能和数据安全性。对于这种方式,Redis使用另一条线程每秒执行fsync同步硬盘。当系统硬盘资源繁忙时,会造成Redis主线程阻塞
AOF线程负责每秒执行一次同步磁盘操作,并记录最近一次同步时间,主线程负责对比上次AOF同步时间
发现两个问题:
1>everysec配置最多可能丢失2秒数据,不是1秒
2>如果系统fsync缓慢,会导致Redis主线程阻塞影响效率
优化AOF追加阻塞主要是优化系统硬盘负载
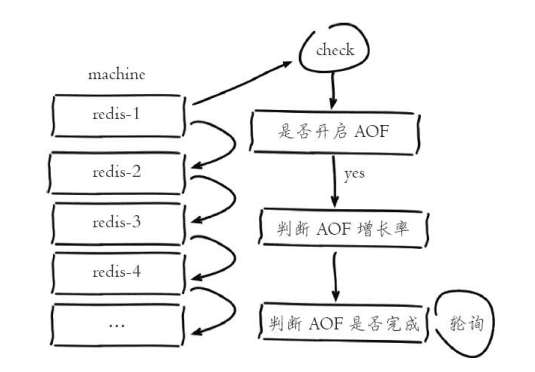
多实例部署:
Redis单线程架构导致无法充分利用CPU多核特性,通常是部署多个Redis实例。当多个实例开启AOF重写后,产生对CPU和IO的竞争
可以通过外部程序轮询控制AOF重写操作的执行:
1>外部程序定时轮询监控机器上所有Redis实例
2>对于开启AOF的实例,查看(aof_current_size-aof_base_size/aof_base_size)确认增长值
3>如果超过特定阈值,执行bgrewriteaof手动触发AOF重写
4>检查增长率指标,知道AOF重写结束
5>确认AOF重写完成后,再检查其他实例,重复 2-4操作,从而保证机器每个Redis实例AOF重写串行化执行
重点总结:
1、RDB使用一次性生成内存快照的方式,产生的文件紧凑压缩比更高,因此读取RDB恢复速度更快。由于每次生成RDB开销较大,无法做到实时性持久化,一般用于数据冷备和复制传输
2、子进程执行期间使用copy-on-write机制与父进程共享内存,避免内存消耗翻倍。AOF重写期间还需要维护重写缓冲区,保存新的写入命令避免数据丢失
3、持久化阻塞主线程场景有:fork阻塞和AOF追加阻塞。fork阻塞时间跟内存量和系统有关,AOF追加阻塞说明硬盘资源紧张
4、单机下部署多个实例,为了防止多个子进程执行重写操作,建议做隔离控制,避免CPU和IO资源竞争
复制:
简易的搭建多个redis实例:
复制一份redis.conf,修改配置文件(redis6380.conf)中的以下属性:
# 修改bind IP
bind 192.168.74.128
# 修改端口号
port 1000
# 以守护进程启动redis
daemonize yes
# 修改pid文件路径
pidfile /data/program/redis-test/redis_1000.pid
# 修改日志级别
loglevel debug
# 修改日志文件路径
logfile /data/program/redis-test/redis_1000.log
1.建立复制,配置复制三种方式
1>配置文件中加入 slaveof host port随着redis启动生效
2>在redis-server启动命令后加入 --seleveof host port 生效
3>直接使用命令 salveof host port生效
2.复制过程
slvaeof 本身是异步命令,执行slaveof命令后,节点只保存主节点信息后返回,后续复制流程在节点内部异步执行
查看 info replication命令查看复制相关状态
3. 执行slaveof no one 来断开复制
执行slaveof newip newport 切换主节点
流程为:断开与旧主节点复制关系,与新主节点建立复制关系,删除从节点当前所有信息,复制新主节点信息
4.安全性
主节点通过设置requirepass参数进行密码验证,这时所有的客户端访问必须使用auth命令实行校验,需要配置从节点masterauth参数与主节点密码保持一致
set config requirepass
auth 密码
5.只读
从节点使用slave-read-only=yes 为只读模式,如果修改会造成主从数据不一致
6.传输延迟
主从节点一般部署在不同机器上,复制时候网络延迟就成为需要考虑的问题。redis提供了repl-disable-tcp-nodelay参数用于控制是否关闭TCP_NODELAY,默认关闭
关闭:及时发送,但增加带宽消耗,适用于主从之间网络良好场景如同机架或同机房
开启:主节点会合并较小TCP从而节省带宽,默认方式时间间隔取决于linux内核,一般40毫秒,省带宽增延迟。适用于主从网络环境复杂或带宽紧张的场景,如夸机房部署
括扑:
redis的复制括扑结构可以支持单层或多层复制关系,根据复杂性可以分为以下三种:一主一从、一主多从、树状主从结果等
1>一主一从:用于主节点出现宕机时从节点提供故障转移支持。
当应用写命令并发量较高且需要持久化时,可以在从节点开启AOF,这样既保证数据安全性同事避免持久化对主节点的性能干扰
注意:主节点关闭持久化时,如果主节点脱机要避免自动重启,因为没有开启持久化自动重启数据集为空,这时从节点如果继续复制主节点会导致数据被清空,安全做法 执行 slaveof no one 然后重启主节点
2>一主多从:实现读写分离
对于读占比较大场景,可以把读命令发送到从节点分担主节点压力,如果执行一些比较耗时读命令,如:keys、sort等,可以在其中一台从节点执行。防止慢查询对主节点造成阻塞从而影响线上服务稳定性,但是多个从节点导致主节点写命令多次发送从而过度消耗网络带宽,加重了主节点负载影响服务稳定性
3>树状主从结构
使得从节点不仅可以复制主节点,同事可以作为其他从节点继续向下层复制,可以有效降低主节点负载和需要传送给从节点的数据量,降低主节点压力
原理:
1、复制过程
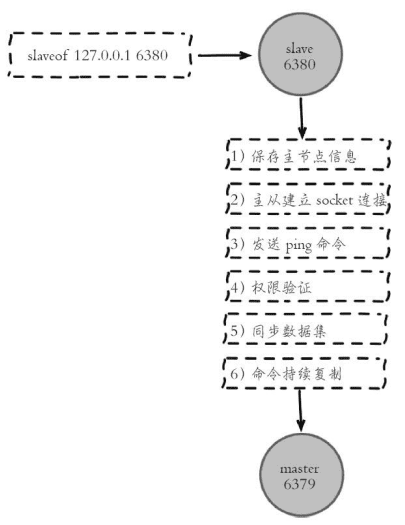
3)发送ping命令目的:检测主从之间网络套接字是否可用、检测主节点当前是否可接受处理命令,如果网络超时或主节点阻塞无法响应命令,从节点断开复制连接,下次定时任务会发起重连
4)如果主节点设置requirepass,需要密码验证
5)同步数据集。分为两种情况:全量同步和部分同步
6)命令持续复制:主节点把当前数据同步给从节点后,完成复制的建立流程。接下来会持续把写命令发送给从节点保证主从数据一致性
数据同步:全量复制、部分复制 psync
全量复制:用于初次复制场景
部分复制:用于处理在主从复制因网络闪断等原因造成数据丢失场景,当从节点连上主节点后,如果条件允许,主节点会补发丢失数据给从节点。因为补发数据远小于全量数据,可以有效避免全量复制的过高开销
psync命令运行需要以下组件支持:主从节点各自复制偏移量、主节点复制积压缓冲区、主节点运行id
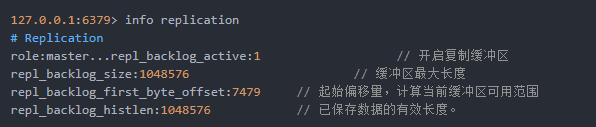
1>参与复制的主从节点都会维护复制偏移量。主节点在处理完写入命令,会把命令字节长度做累加记录,统计在info replication中的master_repl_offset,slave每秒钟上报字节偏移量给主节点,主节点保存 slave_repl_offset
提示:可以判断主从复制相差量判断是否健康
2>复制积压缓冲区(先进先出定长队列)
是保存在主节点上的一个固定长度的队列,默认大小为1MB,当master连接slave时创建,master响应写命令时,不仅把命令发送给从节点,还会写入复制积压缓冲区,实现保存最近已复制数据功能,用于部分复制和复制命令丢失的数据补救
3>主节点运行ID
每个Redis节点启动后都会动态分配一个40位的十六进制字符串作为运行ID。运行ID主要作用是用来唯一识别Redis节点。如果运行ID变化之后从节点将全量复制,运行info server查看 run_id
Redis关闭再启动后,run_id会随之改变
redis关闭:redis-cli -h 127.0.0.1 -p 6379 shutdown
当需要调优一些内存配置,需要redis重启优化已经存在数据,这个时候使用debug reload重新加载RDB保持运行ID不变,有效避免不必要的全量复制
注意:debug reload 会阻塞当前Redis节点主线程,阻塞期间会生成本地RDB快照并清空数据之后加载RDB文件。因此对于大数据量的主节点和无法容忍阻塞的场景不可用
3>主节点运行ID
每个Redis节点启动后都会动态分配一个40位的十六进制字符串作为运行ID。运行ID主要作用是用来唯一识别Redis节点。如果运行ID变化之后从节点将全量复制,运行info server查看 run_id
Redis关闭再启动后,run_id会随之改变
redis关闭:redis-cli -h 127.0.0.1 -p 6379 shutdown
当需要调优一些内存配置,需要redis重启优化已经存在数据,这个时候使用debug reload重新加载RDB保持运行ID不变,有效避免不必要的全量复制
注意:debug reload 会阻塞当前Redis节点主线程,阻塞期间会生成本地RDB快照并清空数据之后加载RDB文件。因此对于大数据量的主节点和无法容忍阻塞的场景不可用
psync命令:
完成部分复制和全量复制功能 psync run_id offset,如果回复+CONTINUE,将触发部分复制流程
如果回复+FULLRESYNC{runId}{offset}触发全量复制,如果回复+ERR,无法识别命令
全量复制:
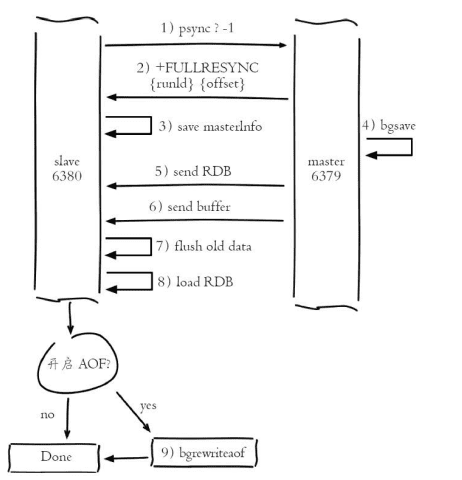
1>发送psync进行数据同步,由于第一次进行复制,从节点没有复制偏移量和主节点运行ID,所以发送 psync-1
2>根据psync-1解析当前为全量复制,回复+FULLRESYNC响应
3>从节点接受保存主节点ID和offset
4>主节点执行bgsave保存RDB文件到本地(M:当前主节点日志 S:当前从节点日志 C:子进程日志)
5>主节点发送RDB给从节点,从节点接受保存到本地并直接作为从节点数据文件,接受完打印相关日志,
为了降低主节点磁盘开销,Redis支持无盘复制,生成的RDB文件不存到硬盘而是直接通过网络发送给从节点通过repl-diskless-sync参数控制,适用于主节点所在机器磁盘性能比较差但网络带宽较充裕的场景
6>对于从节点开始接受RDB到接受完成期间,主节点仍然响应读写命令,因此把这期间命令保存在复制客户端缓冲器内,当丛及诶单加载完,主节点再把缓冲区数据发送从节点,保证主从一致性(默认配置client-output-buffer-limit slave 256 MB 64MB 60,如果60s持续大于64M或者直接超过256,将关闭复制客户端连接 )
7>从节点接受全部数据后会清空自身旧数据
8>加载RDB (slave-server-stale-data 是否响应除了info和slaveof之外其他命令,反之支持不一致)
9>丛及诶单加载完成RDB,如果开启AOF持久化会立刻做bgrewriteaof,保证AOF持久化文件立刻可用
时间开销: 主节点bgsave时间
RDB文件网络传输时间
从节点清空数据时间
从节点加载RDB时间
可能的AOF重写时间
部分复制:
主要是Redis针对全量复制的过高开销做出的一种优化措施,使用psync{run_id}{offset}实现。当slave复制master,如果出现网络闪断或者命令丢失等,slave像master要求补发丢失命令数据,如果master复制积压缓冲区内存在这部分数据则直接发送给从节点,这样保证主从一致
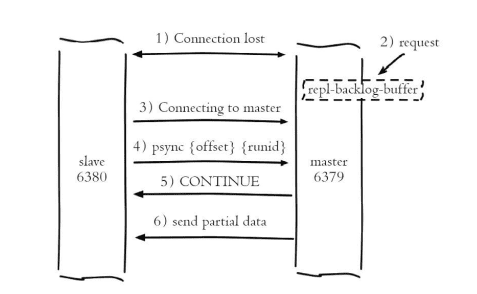
1>主从端口超过repl_timeout时间,主认为从故障并中断复制
2>主仍然响应命令,但是因为复制中端命令无法发送给从,存在复制缓冲区,默认最大1MB
3>当主从网络恢复后,从再次连接上主
4>slave把保存的offer和run_id当做psync参数发送给主,要求部分复制
5>master接收到核对run_id是否与自身意志,如果一直确定是当前主节点,然后根据offset在自身复制积压缓冲区查找,如果偏移量之后数据在缓冲区,则对从发送+continue响应,表示可以部分复制
6>主根据偏移量把缓冲区数据发给从,保证主次进入正常状态
心跳:
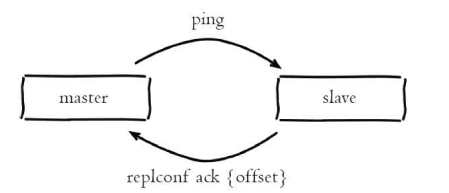
1>主从彼此心跳检测机制,主节点连接状态为flags=M,从为flags=S(client list查看)
2>每隔10s发送ping命令,判断从节点存活性和连接状态。通过repl-ping-slave-period控制发送频率
3>从节点每隔一秒发送 replconf ack {offset},给主当前复制偏移量,主根据replconf判断节点超时时间,体现在info replication统计中lag信息,lag表示与从最后一次通信延迟描述,正常在0和1直接。如果超过repl-timeout(默认60s),从下线并断开连接,主检测从下线,如果从重新恢复,心跳检查继续进行
注意:为了降低主从延迟,一般把Redis主从节点部署在相同机房/同城机房,避免网络延迟和网络分区造成心跳中断
异步复制:
主节点不仅负责数据读取,还负责把写命令同步给从节点。写命令的发送过程是异步的,也就是说主节点自身处理完写命令后直接返回给客户端,并不等待从节点复制完成
因为是异步的,就会造成从节点的数据相对于主节点有延迟,具体延迟多少,可以从info replication查看,正常情况下是1s以内
开发运维的问题总结: 基于复制的应用场景的问题
1.读写分离的时候一般master进行写操作,slave进行读操作,可能遇到以下几个问题:
1>复制数据延迟
2>slave读到旧的数据
3>slave故障
1>数据延迟是不可避免的,主要是网络带宽和命令阻塞造成的,对于无法容忍大量延迟的场景,可以使用外部监听程序定期监听主从的偏移量(info replication),然后差量就是延迟的字节量,当过高的话,监控程序触发报警并通知延迟过高。可以采用Zookeeper的监听回调机制实现客户端通信,接下来修改读命令到其他从节点或主节点。当回复后修改回来。
成本比较高,需要单独修改适配redis的客户端类库,如果涉及多种语言的话成本扩大,还需要维护故障和回复通知,也可以采用Redis集群方案做水平扩展
2>当从节点读到主节点里面有设置超时的缓存数据时候,Redis内部具有自己的删除策略。主要有两种:惰性删除和定时删除
惰性删除:当主节点每次执行读取数据的时候查看数据有没有超时,如果超时执行del,然后也会把del命令发送给从节点,从节点不会主动删除数据。
定时删除:主节点在内部会定时循环采样一些键,发现超时的键执行del,然后同步给从节点
可能出现的问题:如果此时数据大量超时,采样跟不上过期速度且主节点没有读取过期键的操作,从节点无法收到del命令,这时候从节点读取到了超时的数据。这个在Redis 3.2版本解决了这个问题,从节点读取数据会检查键的过期时候在决定是否返回数据
3>从节点故障
在客户端统计可用从节点列表,如果故障切换到其他节点。可以考虑使用Redis Cluster等分布式解决方案
2.主从配置不一致
对于有些配置主从之间可以不一致,比如:主关闭AOF从开启,但是对于内存相关配置必须一致,比如maxmemory,hash-max-ziplist-entries等参数。否者内存从节点小于主节点,会根据maxmemory-policy策略进行内存溢出控制,数据丢失,但是复制照常,偏移量正常,修复的话只能全量复制
3.规避复制风暴
造成原因:大量从节点对同一主节点或者统一台机器多个主节点段时间发起全量复制的过程
1>单节点复制风暴
主要消耗是在主节点发送给多个从节点RDB快照(因为redis的优化,可以使redis共享RDB快照),消耗主节点带宽验证,延迟变大严重时连接断开,导致复制失败
解决:可以采用树形复制结构,网络开销交给中间层的从节点,不必消耗顶层的主节点。
2>单机器复制风暴
由于Redis的单线程架构,通常单台机器部署多个Redis实例,一台机器同时部署多个主节点,当长时间网络中断重启后,多个从节点针对这个机器上的主节点进行全力复制,会造成网络带宽耗尽
解决方案:
a>尽量把主节点分散到多台机器上
b>当主节点故障后提供故障转移机制,避免机器回复后进行秘技的全量复制
总结:主从节点之间维护心跳和偏移检查机制,保证主从节点通信正常和数据一致
Redis保证高效复制是异步的,写命令处理完后直接返回给客户端,不等待从命令复制完成,因此有延迟
主节点存在多个从节点或者一个机器上部署大量主节点情况,可能有复制风暴的风险
Redis的噩梦:阻塞
内在原因:不合理使用API和数据结构、CPU饱和、持久化阻塞
外在原因:CPU竞争、内存互换、网络问题
不合理使用API和数据结构
对于高并发的场景尽量避免在大对象上执行算法复杂度为On的命令,执行slowlog get {n}查看慢查询
1.修改为低算法度命令,如禁止keys、sort(返回给定列表、集合、有序集合经过排序的元素,sort key 从小到大 sort key desc从大到小),hgetall改为hmget等
2.缩减大对象数据或把大对象拆分为多个小对象,防止一次性操作过多的数据
可以使用redis-cli -h -p bigkeys查看大对象,内部原理采用分段进行scan操作,把历史扫描过最大的对象统计出来以便于分析优化
CPU饱和
单线程的redis命令是能使用一个CPU,而CPU饱和是指Redis单核CPU使用率接近百分之百
危害:
导致Reids无法处理更多命令,严重影响吞吐量和应用法的稳定性
查看:
使用top命令识别对应Redis进程的CPU使用率
判断当前Redis的并发量是否达到极限 redis-cli-h -p --stat每秒输出一行统计信息
解决:
例如每秒处理6W+的请求。垂直层面优化很难达到效果,这个时候就需要集群化水平扩展来分摊OPS压力
如果只有几百或者几千OPS的实例就接近CU饱和,可能使用了搞算法复杂度的命令,还有一种情况是过度的内存优化
持久化阻塞:主要引起的原因是 fork阻塞、AOF刷盘阻塞、HugePage写操作阻塞
AOF阻塞主要是RDB和AOF重写时,Redis主线程调用fork操作产生共享内存的子进程的这个期间,导致主线程的阻塞
可以执行info stats 获取 latest_fork_usec直播,标识redis最近一次fork操作耗时如果大的话,就要优化调整,关于fork优化在上面文章详细说明
AOF刷盘阻塞:一般采用每秒一次后台线程对AOF文件做fsync操作。当硬盘压力大时,fsync操作喜悦等待,知道写入完成。如果主线程发现距离上一次的fsync成功超时,为了数据安全性它会阻塞知道后台线程执行fsync操作完成。这种阻塞主要硬盘压力引起的
查看:info persistence中 aof_delayed_fsync指标,每次发生fdatasync阻塞线程时会累加,具体优化看之前AOF追加阻塞部分
HugePage 写操作阻塞:
子进程在执行重写期间利用Linux写时复制技术降低内存开销,因此只有写操作时Redis才复制要修改的内存页。每次写命令引起的复制内存页单位由4K变成2MB,导致大量写操作慢查询。
外在原因:
CPU竞争:
进程竞争:Redis是典型的CPU密集型应用,不建议与其他多核CPU密集型服务部署在一起,其他进程过度消耗CPU时会严重影响Redis吞吐量。通过top等命令定位
绑定CPU:部署Redis时充分利用多核CPU,通常一台机器部署多个实例。常见的优化是吧Redis绑定在一个CPU上,用于降低CPU频繁上下切换的开销。
注意:Redis绑定CPU后父子进程使用一个CPU,当Redis父进程创建子进程进行RDB/AOF重写,子进程重写时将会对单核CPU使用率在90%以上,父子产生激烈的CPU竞争,影响Redis稳定性。因此对于开启了持久化或者参与复制的主节点不建议绑定CPU
内存交换:
Redis保证高性能一个重要前提就是数据在内存中,如果把Redis使用的部分内存换出到硬盘,性能就会急剧下降
检查的办法:
1>查询Redis进程号
redis-cli -p 6379 info server|grep process_id
2>根据进程号查询内存交换信息
cat /proc/进程id/smaps |grep Swap
如果都是0或者个别是4KB则是正常,内存没有被交换
预防的办法:
保证机器充足内存可用,确保Redis设置最大可用内存maxmemory,防止极端情况下Redis内存不可控增长
降低使用swap优先级,如echo10>/proc/sys/vm/swappiness
网络问题:连接拒绝、网络延迟、网卡软中断
Redis内存使用
查询:info memory
used_memory redis分配内存总量
used_memory_ress redis进程占用的物理内存总量
比值:mem_fragmentation_ratio
当>1 说明多出的内存没有数据存储,而是被内存碎片消耗,如果相差很大,说明碎片率严重
当<1 一般是reids内存交换到硬盘导致,redis性能可能会变得很差,甚至僵死
内存消耗:
redis进程内的消耗主要包括:自身内存、对象内存、缓存内存、内存碎片
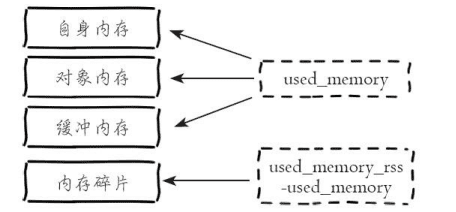
其中redis空进程自身内存消耗非常少,通常used_memory_ress在3MB作用,used_memory在800KB左右
内存对象主要是存储用户所有数据。
缓冲内存:客户端缓存、复制积压缓冲区、AOF缓冲区
内存碎片:
redis分配内存策略一般采用固定范围的内存块进行分配,分为:孝大、巨大三个范围,每个范围内又划分多个小的内存块单位
比如当存5kb话可能采用8kb块存储,剩下的3kb变成了内存碎片不能分配给其他对象。虽然内存碎片是所有内存服务的同步,但是jemalloc针对碎片化问题优化:一般不会存在过度碎片化问题,正常的碎片率在1.03左右。但是当存储数据长短差异较大,以下场景容易出现高内存碎片问题:频繁更新操作、大量过期键删除,释放空间无法得到充分利用导致碎片率上升
解决:
数据对其,尽量采用数字类型或者固定长度字符串
安全重启:重启节点可以做到内存碎片重新整理,可以利用sentinel或集群,将碎片率搞得主换从,安全重启
子进程内存消耗:
主要是指执行AOF\RDB重写时Redis创建的子进程内存消耗。Redis执行fork操作产生的子进程,理论上需要一倍的物理内存完成重写,但是linux具有写时复制,父子共享相同的物理内存页,当父进程处理写请求会对需要修改的页复制一份副本完成写操作,而子进程依然读取fork时整个父进程的内存快照
总结:
1>redis产生子进程并不需要消耗1倍的父进程内存,实际消耗根据期间写入命令量决定,但是依然要预留出一些内存防止溢出
2>需要设置 sysctl vm.overcommit_memory=1允许内核可以分配鄋物理内存,防止redis进程执行fork时因为内存不足而失败
3>关闭THP(降低fork子进程速度,之后写时复制期间内存单位从4KB变成2MB),防止写时复制期间内存过度消耗
内存管理:
Redis主要通过控制内存上线和回收策略实现内存管理
限制内存的目的主要由:
用于缓存场景,当超过内存上线maxmemory时使用LRU等删除策略释放空间
防止所有内存超过服务器物理内存
动态调整:config set mammemroy
如果超过系统物理内存限制就不能调整maxmemory来达到扩容目的,需要采用再现迁移数据或者通过复制切换数据库达到扩容
redis默认无限使用服务器内存,为了防止极端情况导致系统内存耗尽,建议配置maxmemory,在物理内存可用情况,所有Redis实例可以通过调整maxmemory达到自由伸缩内存目的
内存回收策略:
两个方面:删除到达过期时间的键对象、 内存使用达到maxmemory上限时触发内存溢出控制策略
1>redis所有的键都可以设置过期属性,内部保存在过期字典中。由于进程内保存大量的键,维护每个键精准的过期删除机制会导致消耗大量的CPU,对于单线程的Redis成本过高,所以采用惰性和定时任务删除实现过期键的内存回收
惰性删除:当客户端读取带有超时属性的键时,如果超过了过期时间,删除并返回空,处于节省CPU成本高低。但是用这种方式存在内存泄露的问题,当过期键一直没有访问就得不到删除,从而导致内存不能及时释放。
定时任务删除:redis内部维护一个定时任务,默认10次/秒(通过配置hz控制)。定时任务中删除过期键逻辑采用自适应算法,根据键的过期比例、使用快慢两种速率模式回收键
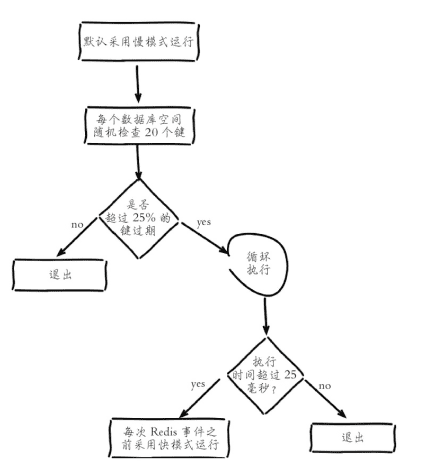
a>定时任务在每个数据库空间随机检查20个键,当发现过期时删除对应的键
b>如果检查超过25%的键过期,循环执行回收策略直到不足25%或者运行超时位置,慢查询下超时时间25毫秒
c>如果之前回收逻辑超时,在redis再次以快模式运行回收过期键任务,快模式下超时时间1毫秒且2秒内只能运行1次
d>快慢两种模式内部删除逻辑相同,只是执行的超时时间不同
2>内存溢出控制策略
具体策略受maxmemory-policy参数控制,redis支持6中策略
a>默认策略:不删除任何数据,拒绝所有写入操作并返回客户端错误信息OOM,此时Redis只响应度操作
b>volatile-lru:根据LRU算法(最近最少使用)删除设置了超时属性(expire)的键,直到腾出空间位置,如果没有可删除的键对象,回到默认策略
c>allkeys-lru:根据LRU算法(最近最少使用)删除键,不管数据有没有设置超时属性,直到腾出空间
d>allkeys-random:随机删除所有键,直到腾出足够空间位置
e>volatile-random:随机删除过期键,直到腾出足够空间位置
f>volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有退回到默认策略
可以通过执行Info stats命令查看evicted_keys查看当前redis因为内存溢出已经删除的键数量
每次redis执行命令如何设置了maxmemory参数都会尝试执行回收内存操作,当redis一只工作在内存溢出(used_memory>maxmemory)且设置非noeviction策略,会频繁吃法回收操作,影响redis性能,成本主要包括回收键和删除键的开销,如果有从节点,回收内存操作也会同步到从节点,导致放大问题
内存的优化:
redis存储的所有值对象在内部定义为redisObjiect结构体
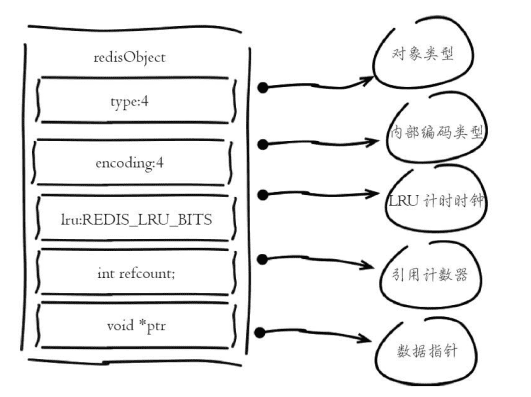
lru字段:记录对象最后一次被访问时间,用于辅助LRU算法
refcount:记录当前对象被引用次数,用于通过引用次数回收内存,当refcount=0,可以安全回收当前对象空间。使用object refcount{key}获取当前对象应用。当对象为整数在[0-9999]时,可以使用共享内存方式节省内存,详细看共享对象池
.*ptr字段:与对象内容有关,如果是整数,直接存储数据;否则标识指向数据的指针。redis在3.0之后对值对象是字符串且长度<=39自己的数据,内部编码为embstr类型,字符串sds和redisObject一起分配,从而只要一次内存操作即可
高并发写入场景中,建议字符串控制在39字节以内,减少创建redisObjct内存分配次数,从而提高性能
共享内存池:
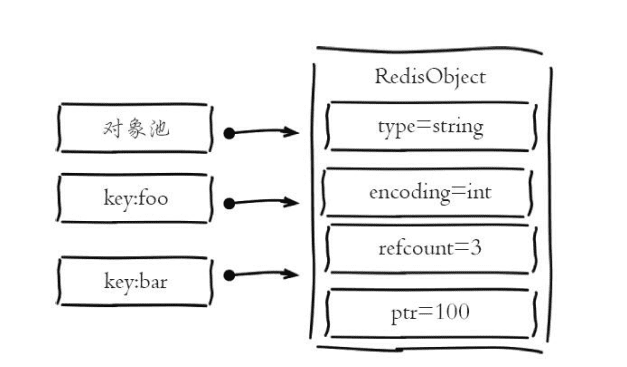
共享对象池是指Redis内部维护[0-9999]的整数对象池。
创建大量的整数类型redisObject存在内存开销,占16字节,甚至超过整数自身空间消耗,所以redis内存维护一个0-9999的整数对象池。除了整数对象,其他类型list、hash、set、zset内部元素也可以使用,所以尽可能使用整数对象以节省内存
使用共享对象池后相同数据内存使用降低30%以上,当设置maxmemory并启用LRU策略:allkeys-lru等,禁止使用共享对象池
原因:LRU算法需要获取对象最后被访问时间,以便淘汰最长为访问数据,每个对象最后访问时间存储在redisObject对象lru字段。对象共享意味着多个引用对象共享同一个redisObject,这时lru字段也会被共享,导致无法获取每个对象最后访问时间。如果没有设置maxmemory,直到内存被用尽redis也不会触发内存回收,所以共享对象池可以正常使用
注意:ziplist即使内部数据为整数也无法使用共享对象池,因为ziplist使用压缩且内存连续的结构,对象共享判断成本过高
为什么只有整数对象池:
首先整数对象池复用几率大,整数比较算法时间复杂度为O1,只保留一万个整数防止对象池浪费。如果是字符串判断时间复杂度为On,浮点数在Redis内部使用字符串存储,对于复杂的数据结构如hash、list等,判断需要On,对于单线程的redis来说,这样开销太大
字符串优化:
结构: redis没有采用原生C语言的字符串类型而是自己实现了字符串结构,动态字符串SDS
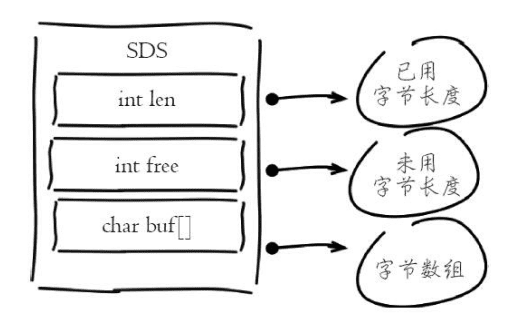
如图:
有如下特点:
O1时间复杂的获取字符串长度、已用长度、未用长度
可用于保存字节数组,支持安全的二进制数据存储
内部实现空间预分配机制,降低内存再分配次数
惰性删除:字符串缩减后空间不释放,作为预分配空间保留
采用预分配是防止修改操作不断分配内存和字节数拷贝,但是同样造成内存浪费,并不是每次都翻倍扩容
1>第一次创建len属性等于数据实际大小,free等于0,不做预分配
2>修改后已有free空间不够且数据小于1M,每次预分配一倍容量
3>如果以后free空间不够且大于1MB,每次预分配1MB数据
结论:尽量减少字符串频繁修改操作如append、setrange,改为直接使用set修改字符串,降低预分配带来的内存浪费和内存碎片化
不一定把每份数据都作为字符串整体存储,像json这样的数据使用hash结构,使用二级结构存储帮我们节省内存,还可以使用hmget、hmset支持部分读取修改,而不用每次整体存取
编码优化: 因为编码不同直接影响数据的内存占用和读取效率 object encoding查看
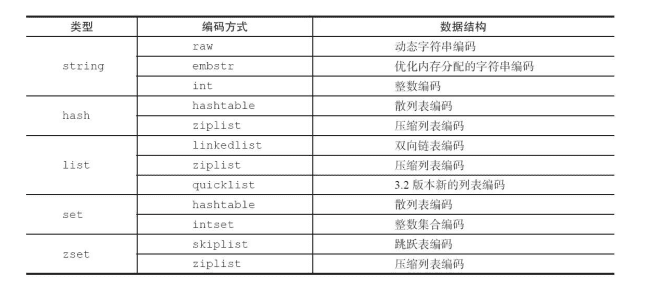
如图:
为什么redis对一种数据结构实现多种编码方式:
redis作者想通过不同编码实现效率和空间的平衡,编码类型实在redis些数据自动完成,转换规则是从小内存编码向大内存编码装换
ziplist:
本文地址:http://www.45fan.com/a/question/99776.html