Heap Sort¶СЕЕРтЛг·ЁөД·Ҫ·ЁҪйЙЬ
1. І»өГІ»ЛөЛө¶юІжКч
ТӘБЛҪв¶СКЧПИөГБЛҪвТ»ПВ¶юІжКчЈ¬ФЪјЖЛг»ъҝЖС§ЦРЈ¬¶юІжКчКЗГҝёцҪЪөгЧо¶аУРБҪёцЧУКчөДКчҪб№№ЎЈНЁіЈЧУКчұ»іЖЧч“ЧуЧУКч”ЈЁleft subtreeЈ©әН“УТЧУКч”ЈЁright subtreeЈ©ЎЈ¶юІжКчіЈұ»УГУЪКөПЦ¶юІжІйХТКчәН¶юІж¶СЎЈ
¶юІжКчөДГҝёцҪбөгЦБ¶аЦ»УР¶юҝГЧУКчЈЁІ»ҙжФЪ¶ИҙуУЪ 2 өДҪбөгЈ©Ј¬¶юІжКчөДЧУКчУРЧуУТЦ®·ЦЈ¬ҙОРтІ»ДЬөЯө№ЎЈ¶юІжКчөДөЪ i ІгЦБ¶аУР 2i - 1 ёцҪбөгЈ»Йо¶ИОӘ k өД¶юІжКчЦБ¶аУР 2k - 1 ёцҪбөгЈ»¶ФИОәОТ»ҝГ¶юІжКч TЈ¬Из№ыЖдЦХ¶ЛҪбөгКэОӘ n0Ј¬¶ИОӘ 2 өДҪбөгКэОӘ n2Ј¬Фтn0 = n2 + 1ЎЈ
КчәН¶юІжКчөДИэёцЦчТӘІоұрЈә
КчөДҪбөгёцКэЦБЙЩОӘ 1Ј¬¶ш¶юІжКчөДҪбөгёцКэҝЙТФОӘ 0
КчЦРҪбөгөДЧоҙу¶ИКэГ»УРПЮЦЖЈ¬¶ш¶юІжКчҪбөгөДЧоҙу¶ИКэОӘ 2
КчөДҪбөгОЮЧуЎўУТЦ®·ЦЈ¬¶ш¶юІжКчөДҪбөгУРЧуЎўУТЦ®·Ц
¶юІжКчУЦ·ЦОӘНкИ«¶юІжКчЈЁcomplete binary treeЈ©әНВъ¶юІжКчЈЁfull binary treeЈ©
Въ¶юІжКчЈәТ»ҝГЙо¶ИОӘ kЈ¬ЗТУР 2k - 1 ёцҪЪөгіЖЦ®ОӘВъ¶юІжКч
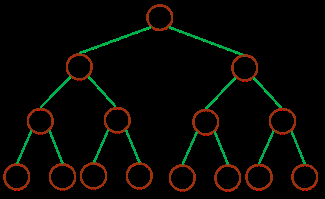
ЈЁЙо¶ИОӘ 3 өДВъ¶юІжКч full binary treeЈ©
НкИ«¶юІжКчЈәЙо¶ИОӘ kЈ¬УР n ёцҪЪөгөД¶юІжКчЈ¬өұЗТҪцөұЖдГҝТ»ёцҪЪөг¶јУлЙо¶ИОӘ k өДВъ¶юІжКчЦРРтәЕОӘ 1 ЦБ n өДҪЪөг¶ФУҰКұЈ¬іЖЦ®ОӘНкИ«¶юІжКч
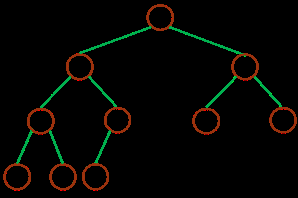
ЈЁЙо¶ИОӘ 3 өДНкИ«¶юІжКч complete binary treeЈ©
2. КІГҙКЗ¶СЈҝ
¶СЈЁ¶юІж¶СЈ©ҝЙТФКУОӘТ»ҝГНкИ«өД¶юІжКчЈ¬НкИ«¶юІжКчөДТ»ёц“УЕРг”өДРФЦККЗЈ¬іэБЛЧоөЧІгЦ®НвЈ¬ГҝТ»Іг¶јКЗВъөДЈ¬ХвК№өГ¶СҝЙТФАыУГКэЧйАҙұнКҫЈЁЖХНЁөДТ»°гөД¶юІжКчНЁіЈУГБҙұнЧчОӘ»щұҫИЭЖчұнКҫЈ©Ј¬ГҝТ»ёцҪбөг¶ФУҰКэЧйЦРөДТ»ёцФӘЛШЎЈ
ИзПВНјЈ¬КЗТ»ёц¶СәНКэЧйөДПа»Ҙ№ШПө
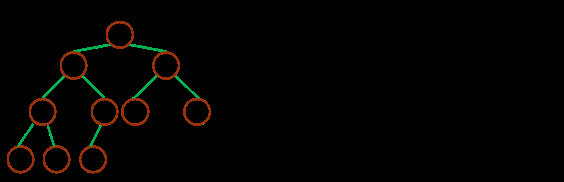
ЈЁ¶СәНКэЧйөДПа»Ҙ№ШПөЈ©
¶ФУЪёш¶ЁөДДіёцҪбөгөДПВұк iЈ¬ҝЙТФәЬИЭТЧөДјЖЛгіцХвёцҪбөгөДёёҪбөгЎўәўЧУҪбөгөДПВұкЈә
Parent(i) = floor(i/2)Ј¬i өДёёҪЪөгПВұк
Left(i) = 2iЈ¬i өДЧуЧУҪЪөгПВұк
Right(i) = 2i + 1Ј¬i өДУТЧУҪЪөгПВұк

¶юІж¶СТ»°г·ЦОӘБҪЦЦЈәЧоҙу¶СәНЧоРЎ¶СЎЈ
Чоҙу¶СЈә
Чоҙу¶СЦРөДЧоҙуФӘЛШЦөіцПЦФЪёщҪбөгЈЁ¶С¶ҘЈ©
¶СЦРГҝёцёёҪЪөгөДФӘЛШЦө¶јҙуУЪөИУЪЖдәўЧУҪбөгЈЁИз№ыҙжФЪЈ©
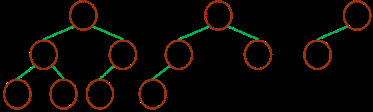
ЈЁЧоҙу¶СЈ©
ЧоРЎ¶СЈә
ЧоРЎ¶СЦРөДЧоРЎФӘЛШЦөіцПЦФЪёщҪбөгЈЁ¶С¶ҘЈ©
¶СЦРГҝёцёёҪЪөгөДФӘЛШЦө¶јРЎУЪөИУЪЖдәўЧУҪбөгЈЁИз№ыҙжФЪЈ©
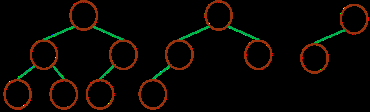
ЈЁЧоРЎ¶СЈ©
3. ¶СЕЕРтФӯАн
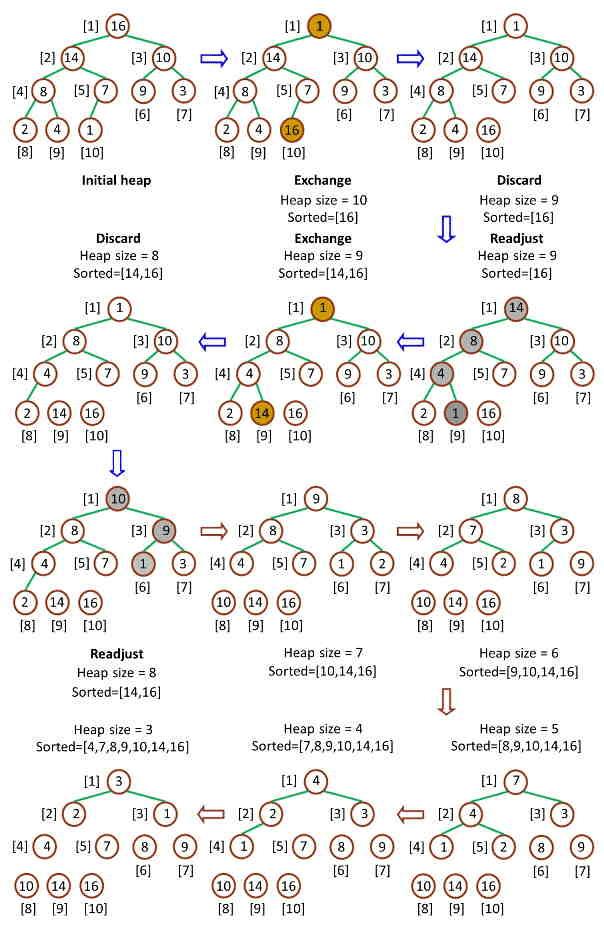
¶СЕЕРтҫНКЗ°СЧоҙу¶С¶С¶ҘөДЧоҙуКэИЎіцЈ¬Ҫ«КЈУаөД¶СјМРшөчХыОӘЧоҙу¶СЈ¬ФЩҙОҪ«¶С¶ҘөДЧоҙуКэИЎіцЈ¬Хвёц№эіМіЦРшөҪКЈУаКэЦ»УРТ»ёцКұҪбКшЎЈФЪ¶СЦР¶ЁТеТФПВјёЦЦІЩЧчЈә
Чоҙу¶СөчХыЈЁMax-HeapifyЈ©ЈәҪ«¶СөДД©¶ЛЧУҪЪөгЧчөчХыЈ¬К№өГЧУҪЪөгУАФ¶РЎУЪёёҪЪөг
ҙҙҪЁЧоҙу¶СЈЁBuild-Max-HeapЈ©ЈәҪ«¶СЛщУРКэҫЭЦШРВЕЕРтЈ¬К№ЖдіЙОӘЧоҙу¶С
¶СЕЕРтЈЁHeap-SortЈ©ЈәТЖіэО»ФЪөЪТ»ёцКэҫЭөДёщҪЪөгЈ¬ІўЧцЧоҙу¶СөчХыөДөЭ№йФЛЛг
јМРшҪшРРПВГжөДМЦВЫЗ°Ј¬РиТӘЧўТвөДТ»ёцОКМвКЗЈәКэЧй¶јКЗ Zero-BasedЈ¬ХвҫНТвО¶ЧЕОТГЗөД¶СКэҫЭҪб№№ДЈРНТӘ·ўЙъёДұд
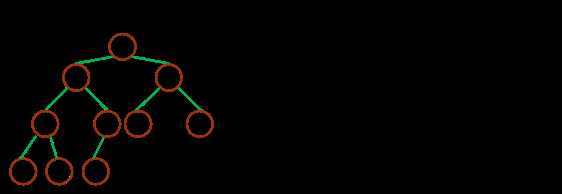
ЈЁZero-BasedЈ©
ПаУҰөДЈ¬јёёцјЖЛ㹫КҪТІТӘЧчіцПаУҰөчХыЈә
Parent(i) = floor((i-1)/2)Ј¬i өДёёҪЪөгПВұк
Left(i) = 2i + 1Ј¬i өДЧуЧУҪЪөгПВұк
Right(i) = 2(i + 1)Ј¬i өДУТЧУҪЪөгПВұк
Чоҙу¶СөчХыЈЁMAX©\HEAPIFYЈ©өДЧчУГКЗұЈіЦЧоҙу¶СөДРФЦКЈ¬КЗҙҙҪЁЧоҙу¶СөДәЛРДЧУіМРтЈ¬ЧчУГ№эіМИзНјЛщКҫЈә
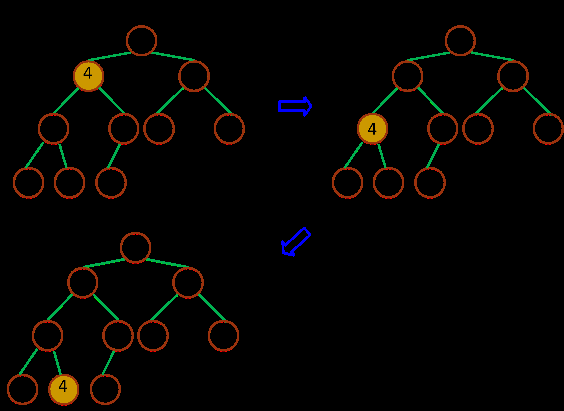
ЈЁMax-HeapifyЈ©
УЙУЪТ»ҙОөчХыә󣬶СИФИ»ОҘ·ҙ¶СРФЦКЈ¬ЛщТФРиТӘөЭ№йөДІвКФЈ¬К№өГХыёц¶С¶јВъЧг¶СРФЦКЈ¬УГ JavaScript ҝЙТФұнКҫИзПВЈә
/**
* ҙУ index ҝӘКјјмІйІўұЈіЦЧоҙу¶СРФЦК
*
* @array
*
* @index јмІйөДЖрКјПВұк
*
* @heapSize ¶СҙуРЎ
*
**/
function maxHeapify(array, index, heapSize) {
var iMax = index,
iLeft = 2 * index + 1,
iRight = 2 * (index + 1);
if (iLeft < heapSize && array[index] < array[iLeft]) {
iMax = iLeft;
}
if (iRight < heapSize && array[iMax] < array[iRight]) {
iMax = iRight;
}
if (iMax != index) {
swap(array, iMax, index);
maxHeapify(array, iMax, heapSize); // өЭ№йөчХы
}
}
function swap(array, i, j) {
var temp = array[i];
array[i] = array[j];
array[j] = temp;
}
НЁіЈАҙЛөЈ¬өЭ№йЦчТӘУГФЪ·ЦЦО·ЁЦРЈ¬¶шХвАпІўІ»РиТӘ·ЦЦОЎЈ¶шЗТөЭ№йөчУГРиТӘС№Х»/ЗеХ»Ј¬әНөьҙъПаұИЈ¬РФДЬЙПУРВФОўөДБУКЖЎЈөұИ»Ј¬°ҙХХ20/80·ЁФтЈ¬ХвКЗҝЙТФәцВФөДЎЈө«КЗИз№ыДгҫхөГУГөЭ№й»бИГЧФјәРДАп№эІ»ИҘөД»°Ј¬ТІҝЙТФУГөьҙъЈ¬ұИИзПВГжХвСщЈә
/**
* ҙУ index ҝӘКјјмІйІўұЈіЦЧоҙу¶СРФЦК
*
* @array
*
* @index јмІйөДЖрКјПВұк
*
* @heapSize ¶СҙуРЎ
*
**/
function maxHeapify(array, index, heapSize) {
var iMax, iLeft, iRight;
while (true) {
iMax = index;
iLeft = 2 * index + 1;
iRight = 2 * (index + 1);
if (iLeft < heapSize && array[index] < array[iLeft]) {
iMax = iLeft;
}
if (iRight < heapSize && array[iMax] < array[iRight]) {
iMax = iRight;
}
if (iMax != index) {
swap(array, iMax, index);
index = iMax;
} else {
break;
}
}
}
function swap(array, i, j) {
var temp = array[i];
array[i] = array[j];
array[j] = temp;
}
ҙҙҪЁЧоҙу¶СЈЁBuild-Max-HeapЈ©өДЧчУГКЗҪ«Т»ёцКэЧйёДФміЙТ»ёцЧоҙу¶СЈ¬ҪУКЬКэЧйәН¶СҙуРЎБҪёцІОКэЈ¬Build-Max-Heap Ҫ«ЧФПВ¶шЙПөДөчУГ Max-Heapify АҙёДФмКэЧйЈ¬ҪЁБўЧоҙу¶СЎЈТтОӘ Max-Heapify ДЬ№»ұЈЦӨПВұк i өДҪбөгЦ®әуҪбөг¶јВъЧгЧоҙу¶СөДРФЦКЈ¬ЛщТФЧФПВ¶шЙПөДөчУГ Max-Heapify ДЬ№»ФЪёДФм№эіМЦРұЈіЦХвТ»РФЦКЎЈИз№ыЧоҙу¶СөДКэБҝФӘЛШКЗ nЈ¬ДЗГҙ Build-Max-Heap ҙУ Parent(n) ҝӘКјЈ¬НщЙПТАҙОөчУГ Max-HeapifyЎЈБчіМИзПВЈә
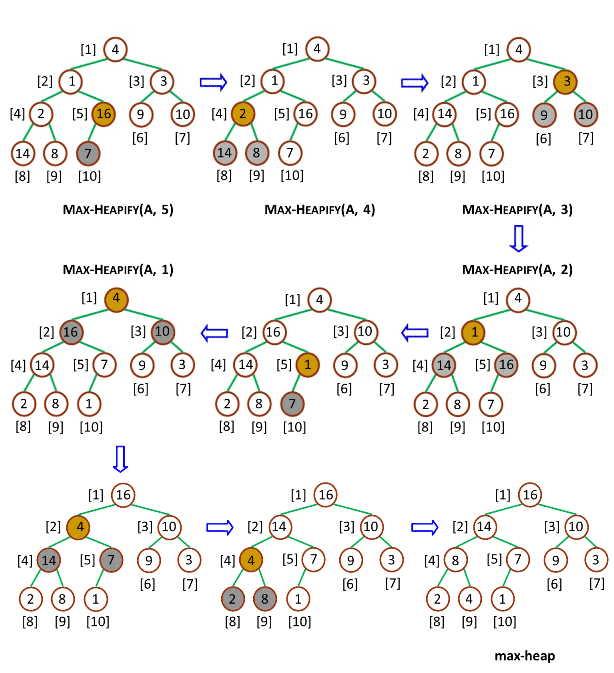
УГ JavaScript ГиКцИзПВЈә
function buildMaxHeap(array, heapSize) {
var i,
iParent = Math.floor((heapSize - 1) / 2);
for (i = iParent; i >= 0; i--) {
maxHeapify(array, i, heapSize);
}
}
¶СЕЕРтЈЁHeap-SortЈ©КЗ¶СЕЕРтөДҪУҝЪЛг·ЁЈ¬Heap-SortПИөчУГBuild-Max-HeapҪ«КэЧйёДФмОӘЧоҙу¶СЈ¬И»әуҪ«¶С¶ҘәН¶СөЧФӘЛШҪ»»»Ј¬Ц®әуҪ«өЧІҝЙПЙэЈ¬ЧоәуЦШРВөчУГMax-HeapifyұЈіЦЧоҙу¶СРФЦКЎЈУЙУЪ¶С¶ҘФӘЛШұШИ»КЗ¶СЦРЧоҙуөДФӘЛШЈ¬ЛщТФТ»ҙОІЩЧчЦ®ә󣬶СЦРҙжФЪөДЧоҙуФӘЛШұ»·ЦАліц¶СЈ¬ЦШёҙn-1ҙОЦ®әуЈ¬КэЧйЕЕБРНкұПЎЈХыёцБчіМИзПВЈә
УГ JavaScript ГиКцИзПВЈә
function heapSort(array, heapSize) {
buildMaxHeap(array, heapSize);
for (int i = heapSize - 1; i > 0; i--) {
swap(array, 0, i);
maxHeapify(array, 0, i);
}
}
4.JavaScript УпСФКөПЦ
ЧоәуЈ¬°СЙПГжөДХыАнОӘНкХыөД javascript ҙъВлИзПВЈә
function heapSort(array) {
function swap(array, i, j) {
var temp = array[i];
array[i] = array[j];
array[j] = temp;
}
function maxHeapify(array, index, heapSize) {
var iMax,
iLeft,
iRight;
while (true) {
iMax = index;
iLeft = 2 * index + 1;
iRight = 2 * (index + 1);
if (iLeft < heapSize && array[index] < array[iLeft]) {
iMax = iLeft;
}
if (iRight < heapSize && array[iMax] < array[iRight]) {
iMax = iRight;
}
if (iMax != index) {
swap(array, iMax, index);
index = iMax;
} else {
break;
}
}
}
function buildMaxHeap(array) {
var i,
iParent = Math.floor(array.length / 2) - 1;
for (i = iParent; i >= 0; i--) {
maxHeapify(array, i, array.length);
}
}
function sort(array) {
buildMaxHeap(array);
for (var i = array.length - 1; i > 0; i--) {
swap(array, 0, i);
maxHeapify(array, 0, i);
}
return array;
}
return sort(array);
}
5.¶СЕЕРтЛг·ЁөДФЛУГ
ЈЁ1Ј©Лг·ЁРФДЬ/ёҙФУ¶И
¶СЕЕРтөДКұјдёҙФУ¶И·ЗіЈОИ¶ЁЈЁОТГЗҝЙТФҝҙөҪЈ¬¶ФКдИлКэҫЭІ»ГфёРЈ©Ј¬ОӘO(n©Sn)ёҙФУ¶ИЈ¬ЧоәГЗйҝцУлЧо»өЗйҝцТ»СщЎЈ
ө«КЗЈ¬ЖдҝХјдёҙФУ¶ИТАКөПЦІ»Н¬¶шІ»Н¬ЎЈЙПГжјҙМЦВЫБЛБҪЦЦіЈјыөДёҙФУ¶ИЈәO(n)УлO(1)ЎЈұҫЧЕҪЪФјҝХјдөДФӯФтЈ¬ОТНЖјцO(1)ёҙФУ¶ИөД·Ҫ·ЁЎЈ
ЈЁ2Ј©Лг·ЁОИ¶ЁРФ
¶СЕЕРтҙжФЪҙуБҝөДЙёСЎәНТЖ¶Ҝ№эіМЈ¬КфУЪІ»ОИ¶ЁөДЕЕРтЛг·ЁЎЈ
ЈЁ3Ј©Лг·ЁККУГіЎҫ°
¶СЕЕРтФЪҪЁБў¶СәНөчХы¶СөД№эіМЦР»бІъЙъұИҪПҙуөДҝӘПъЈ¬ФЪФӘЛШЙЩөДКұәтІўІ»ККУГЎЈө«КЗЈ¬ФЪФӘЛШұИҪП¶аөДЗйҝцПВЈ¬»№КЗІ»ҙнөДТ»ёцСЎФсЎЈУИЖдКЗФЪҪвҫцЦоИз“З°nҙуөДКэ”Т»АаОКМвКұЈ¬јёәхКЗКЧСЎЛг·ЁЎЈ
ұҫОДөШЦ·Јәhttp://www.45fan.com/bcdm/60397.html