如何使用ADS1.2进行嵌入式软件开发?
作者:ARM公司来源:eepw.com.cn 概述嵌入式应用程序通常都是在样机环境下调试与开发的,这种环境与最终产品之间并不完全相同。因此,在系统调试阶段就考虑应用程序在最终目标硬件中的运行情况是非常重要的。本文旨在讨论如何将一个开发/调试环境下的嵌入式应用程序转移到最终独立运行的目标系统中去,并提到了ARMADS1.2开发工具包的一些功能特性及其在这个过程中所起到的作用。 使用ADS开发嵌入式程序时,需要着重考虑以下几个问题: 1.与硬件相关的C语言库函数的使用; 2.某些C语言库函数使用了调试环境中的资源,要把这些使用的资源重定向到目标系统中的硬件上来; 3.可执行映象文件的存储器映射必须根据目标硬件的存储器分布进行裁剪; 4.在主程序执行前,嵌入式应用程序必须先完成系统的初始化。一个完整的初始化包括用户的启动执行代码和ADS中C库函数的初始化过程。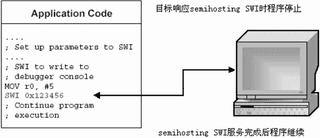 图1Semihosting的实现举例
图1Semihosting的实现举例 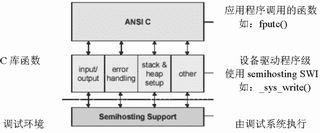 图2C语言库函数结构
图2C语言库函数结构 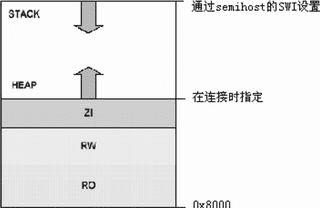 图3缺省的存储器映射
图3缺省的存储器映射 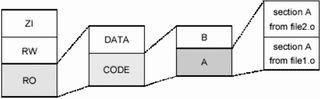 图4连接器布局规则 缺省的工程项目设置刚 开始一个嵌入式应用软件开发时,ADS用户可能并不完全清楚目标硬件的一些参数指标。比如有关外设、存储器地址分布,甚至处理器类型等一些细节,可能还没 有最终确定。为了在所有这些细节全部就绪前就能进行软件开发,ADS工具有一套程序构建和调试的缺省设置。了解这套缺省的工程项目设置方法,对于掌握最终 的移植步骤非常有好处。 ADS1.2C语言函数库 Semihosting 在ADS的C语言函数库中,某些 ANSIC的功能是由主机的调试环境来提供的,这套机制有一个专门术语叫Semihosting。Semihosting通过一组软件中断(SWI)指令 来实现。如图1所示,当一个Semihosting软中断被执行时,调试系统先识别这个SWI请求,然后挂起正在运行的程序,调用Semihosting 的服务,完成后再恢复原来的程序执行。因此,主机执行的任务对于程序来说是透明的。 C语言库函数结构从概念上来讲,C语言库函数可以被分成两部分,一是ANSIC语言规范本身的一部分,一是只受某一特定ANSIC层次支持的函数,如图2所示。其 中一些ANSIC的功能是由主机调试环境调用驱动程序级的函数完成的。例如,ADS的库函数printf()把输出信息输出到调试器的控制台窗口,这个功 能通过调用__sys_write()实现,__sys_write()执行了一个把字符串输出到主机控制台的Semihosting软中断服务程序。 缺省的存储器映射如果用户在程序编译时没有指定映象的存储器映射分布,ADS将为生成的目标代码和数据分配一个缺省的存储器映射图,如图3所示。目标印象被连接至地址0x8000,存储和执行区域都位于该地址开始的空间。RO(只读)部分放在前面,接着是RW(读写)部分,最后是ZI(零初始化)部分。在ZI部分之上紧跟着HEAP,所以HEAP的确切地址要在连接时才能确定。 STACK的基地址是在应用程序启动时由一个Semihosting操作提供。这项Semihosting操作返回的地址值视不同调试环境而定: ARMulator返回配置文件peripherals.ami中的设置值;缺省为0x08000000。 Multi-ICE返回的是调试器内部变量$top_of_memory的值;缺省为0x00080000。 连接器布局规则连接器对代码和数据在存储器系统中的分配,遵循一套规则,如图4所示。映 象首先按照属性以RO-RW-ZI的次序进行排列,在同一种属性里面代码先于数据。然后连接器将输入段根据名字的字母顺序进行排列,输入段的名字与汇编代 码里面的块名字指示一致(在汇编程序中用AREA关键字)。在输入段中,来自不同对象的代码和数据放置次序与在连接器命令行中指定的对象文件次序一致。在需要灵活分配代码和数据放置位置的情况下,建议用户不要简单地依靠这些规则。后面会介绍一种如何控制代码和数据布局的机制Scatterloading。
图4连接器布局规则 缺省的工程项目设置刚 开始一个嵌入式应用软件开发时,ADS用户可能并不完全清楚目标硬件的一些参数指标。比如有关外设、存储器地址分布,甚至处理器类型等一些细节,可能还没 有最终确定。为了在所有这些细节全部就绪前就能进行软件开发,ADS工具有一套程序构建和调试的缺省设置。了解这套缺省的工程项目设置方法,对于掌握最终 的移植步骤非常有好处。 ADS1.2C语言函数库 Semihosting 在ADS的C语言函数库中,某些 ANSIC的功能是由主机的调试环境来提供的,这套机制有一个专门术语叫Semihosting。Semihosting通过一组软件中断(SWI)指令 来实现。如图1所示,当一个Semihosting软中断被执行时,调试系统先识别这个SWI请求,然后挂起正在运行的程序,调用Semihosting 的服务,完成后再恢复原来的程序执行。因此,主机执行的任务对于程序来说是透明的。 C语言库函数结构从概念上来讲,C语言库函数可以被分成两部分,一是ANSIC语言规范本身的一部分,一是只受某一特定ANSIC层次支持的函数,如图2所示。其 中一些ANSIC的功能是由主机调试环境调用驱动程序级的函数完成的。例如,ADS的库函数printf()把输出信息输出到调试器的控制台窗口,这个功 能通过调用__sys_write()实现,__sys_write()执行了一个把字符串输出到主机控制台的Semihosting软中断服务程序。 缺省的存储器映射如果用户在程序编译时没有指定映象的存储器映射分布,ADS将为生成的目标代码和数据分配一个缺省的存储器映射图,如图3所示。目标印象被连接至地址0x8000,存储和执行区域都位于该地址开始的空间。RO(只读)部分放在前面,接着是RW(读写)部分,最后是ZI(零初始化)部分。在ZI部分之上紧跟着HEAP,所以HEAP的确切地址要在连接时才能确定。 STACK的基地址是在应用程序启动时由一个Semihosting操作提供。这项Semihosting操作返回的地址值视不同调试环境而定: ARMulator返回配置文件peripherals.ami中的设置值;缺省为0x08000000。 Multi-ICE返回的是调试器内部变量$top_of_memory的值;缺省为0x00080000。 连接器布局规则连接器对代码和数据在存储器系统中的分配,遵循一套规则,如图4所示。映 象首先按照属性以RO-RW-ZI的次序进行排列,在同一种属性里面代码先于数据。然后连接器将输入段根据名字的字母顺序进行排列,输入段的名字与汇编代 码里面的块名字指示一致(在汇编程序中用AREA关键字)。在输入段中,来自不同对象的代码和数据放置次序与在连接器命令行中指定的对象文件次序一致。在需要灵活分配代码和数据放置位置的情况下,建议用户不要简单地依靠这些规则。后面会介绍一种如何控制代码和数据布局的机制Scatterloading。 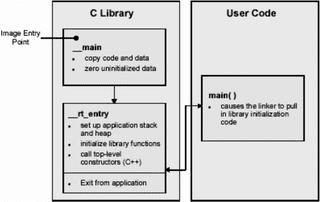 图5缺省的ADS初始化过程
图5缺省的ADS初始化过程 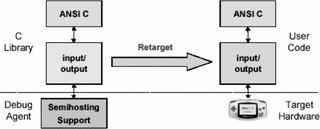 图6C库函数重定向
图6C库函数重定向 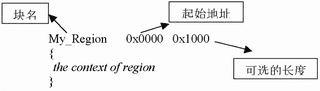 图7scatter文件语法
图7scatter文件语法 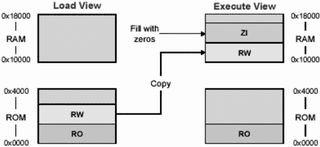 图8分散加载的简单样例 启动应用程序大多数嵌入式系统在进入应用主程序之前有一个初始化的过程,该过程完成系统的启动和初始化功能。缺省的ADS初始化过程如图5所示。总体上,初始化过程可以分成两部分来看: _main负责设置运行映像存储器映射; _rt_entry负责库函数的初始化。 _main 完成代码和数据的复制,并把ZI数据区清零。这一步只有当代码和数据区在存储和运行时处于不同的存储器位置时才有意义。接着_main跳进 _rt_entry,进行STACK和HEAP等的初始化。最后_rt_entry跳进应用程序的入口main()。当应用程序执行完时, _rt_entry又将控制权交还给调试器。函数main()在ADS中有特殊的意义。当一个程序工程项目中存在main()时,连接器会把_main和_rt_entry中的初始化代码连接进来;如果没有main()函数,初始化过程就不会被连接,结果就会导致一些标准的C库函数无效。 根据目标环境裁减C库函数缺省状态下C库函数利用Semihotsting机制来实现设备驱动的功能。但一个真正的嵌入式系统,要使用到具体的外设或硬件独立于主机环境运行。 C库函数重定向用户可以定义自己的C语言库函数,连接器在连接时自动使用这些新的功能函数。这个过程叫做重定向C语言库函数,如图6所示。举例来说,用户有一个I/O设备(如UART)。本来库函数fputc()是把字符输出到调试器控制窗口中去的,但用户把输出设备改成了UART端口,这样一来,所有基于fputc()函数的printf()系列函数输出都被重定向到UART端口上去了。下面是实现fputc()重定向的一个例子: externvoidsendchar(char*ch); intfputc(intch,FILE*f) {/*e.g.writeacharactertoanUART*/ chartempch=ch; sendchar(&tempch); returnch; }这个例子简单地将输入字符重新定向到另一个函数sendchar(),sendchar()假定是一个另外定义的串口输出函数。在这里,fputc()就好像目标硬件和标准C库函数之间的一个抽象层。 在C语言库函数中禁用Semihosting 在一个独立的嵌入式应用程序中,应该不存在SemihostingSWI操作。因此,用户必须确定在所有调用到的库函数中没有使用Semihosting。为了保证这一点,在程序中可以引进一个符号关键字_use_no_semihosting:在C代码中,使用#prgrama#pragmaimport〈_use_no_semihosting_swi〉在汇编程序中,使用IMPORT IMPORT_use_no_semihosting_swi 这样,当有使用SWI机制的库函数被连接时,连接器会进行报错: Error:Symbol_semihosting_swi_guardmultiplydefined 为了确定具体是哪一个函数,连接时打开-verbose选项。这样在结果信息输出时,该库函数上将有一个_I_use_semihosting_swi的标记。 Loadingmembersys_wxit.ofromc_a_un.1. Definition:_sys_exit Reference:_I_use_semihosting_swi 用户必须要把这些函数定义成自己的执行内容。有一点需要注意,连接器只能报告库函数中被调用的Semihosting,对用户自定义函数中使用的Semihosting则不会报错。 根据目标硬件定制存储器映射分散装载(Scatlerloading) 在实际的嵌入式系统中,ADS提供的缺省存储器映射是不能满足要求的。用户的目标硬件通常有多个存储器设备位于不同的位置,并且这些存储器设备在程序装载和运行时可能还有不同的配置。 Scattertoading可以通过一个文本文件来指定一段代码或数据在加载和运行时在存储器中的不同位置。这个文本文件scatterfile在命令行中由-scatter开关指定,例如: armlink_scatterscat.scffilel.ofile2.0 在scatterfile中可以为每一个代码或数据区在装载和执行时指定不同的存储区域地址,Scatlertoading的存储区块可以分成二种类型:装载区:当系统启动或加载时应用程序的存放区。执行区:系统启动后,应用程序进行执行和数据访问的存储器区域,系统在实时运行时可以有一个或多个执行块。映像中所有的代码和数据都有一个装载地址和运行地址(二者可能相同也可能不同,视具体情况而定)。在系统启动时,C函数库中的__main初始化代码会执行必要的复制及清零操作,使应用程序的相应代码和数据段从装载状态转入执行状态。 1.scatter文件语法 scatter文件是一个简单的文本文件,包含一些简单的语法。 My_Region0x00000x1000 { thecontextofregion } 每个块由一个头标题开始定义,头中至少包含块的名字和起始地址,另外还有最大长度和其他一些属性选项。块定义的内容包括在紧接的一对花括号内,依赖于具体的系统情况。一个加载块必须至少含有一个执行块;实践中通常有多个执行块。一个执行块必须至少含有一个代码或数据段;这些通常来自源文件或库函数等的目标文件;通配符号*可以匹配指定属性项中所有没有在文件中定义的余下部分。 2.简单分散加载样例图8 所示样例中,只有一个加载块,包含了所有的代码和数据,起始地址为0。这个加载块一共对应两个执行块。一个包含所有的RO代码和数据,执行地址与装载地址 相同;同时另一个起始地址为0x10000的执行块,包含所有的RW和ZI数据。这样当系统开始启动时,从第一个执行块开始运行(执行地址等于装载地 址),在执行过程中,有一段初始化代码会把装载块中的一部分代码转移到另外的执行块中。下面是这个scatter描述文件,该文件描述了上述存储器映射方式。 LOAD_ROM0x4000 { EXE_ROM0x00000x4000;Rootregion { *〈+RO〉;Allcodeandconstantdata } RAM0x100000x8000 { *〈+RW,+ZI〉;Allnon-constantdata }} 3.在分散文件中放置对象在大多数应用中,并不是像前例那样,简单地把所有属性都放在一起,用户需要控制特定代码和数据段的放置位置。这可以通过在scatter文件中对单个目标文件进行定义实现,而不是只简单地依靠通配符。为了覆盖标准的连接器布局规则,我们可以使用+FIRST和+LAST分散加载指令。典型的例子是在执行块的开始处放置中断向量表格: LOAD_ROM0x00000x4000 { EXEC_ROM0x00000x4000 { vectors.o〈Vect,+FIRST〉 *〈+RO〉} ;moreexecregions... }在这个scatter文件中,保证了vextors.o中的Vect域被放置于地址0x0000。 4.RootRegion(根区) 根区是一个执行块,它的加载地址与执行地址是一致的。每个scatter文件至少有一个根区。分散加载有一个限制:创建执行块的代码和数据(即完成复制和清零的代码和数据)无法自行复制到另一个位置。因此,在根区中必须含有下面的部分: _main.o,包含复制代码/数据的代码;连接器输出变量$$Table和ZISection$$Table,包含被复制代码/数据的地址。由于上面两个部分的属性是只读的,因此他们被*〈+RO〉通配符语法匹配。如果*〈+RO〉被用在了非根区中,则在根区中必须显式地指明另一个RO区域。下面是一个例子: LOAD_ROM0x00000x4000 { EXE_ROM0x00000x4000;rootregion { _main.o〈+RO〉;copyingcode *〈Region$$Tabl0e〉;RO/RWaddressestocopy *〈ZISection$$Table〉;ZIaddressestozero } RAM0x100000x8000 { *〈+RO〉;allotherROsections *〈+RW,+ZI〉;allRWandZIsections }} (待续)在下期中将更详细介绍利用scatter文件进行存储器配置的方法,以及系统启动和初始化的过程和存储器映射变化关系。
图8分散加载的简单样例 启动应用程序大多数嵌入式系统在进入应用主程序之前有一个初始化的过程,该过程完成系统的启动和初始化功能。缺省的ADS初始化过程如图5所示。总体上,初始化过程可以分成两部分来看: _main负责设置运行映像存储器映射; _rt_entry负责库函数的初始化。 _main 完成代码和数据的复制,并把ZI数据区清零。这一步只有当代码和数据区在存储和运行时处于不同的存储器位置时才有意义。接着_main跳进 _rt_entry,进行STACK和HEAP等的初始化。最后_rt_entry跳进应用程序的入口main()。当应用程序执行完时, _rt_entry又将控制权交还给调试器。函数main()在ADS中有特殊的意义。当一个程序工程项目中存在main()时,连接器会把_main和_rt_entry中的初始化代码连接进来;如果没有main()函数,初始化过程就不会被连接,结果就会导致一些标准的C库函数无效。 根据目标环境裁减C库函数缺省状态下C库函数利用Semihotsting机制来实现设备驱动的功能。但一个真正的嵌入式系统,要使用到具体的外设或硬件独立于主机环境运行。 C库函数重定向用户可以定义自己的C语言库函数,连接器在连接时自动使用这些新的功能函数。这个过程叫做重定向C语言库函数,如图6所示。举例来说,用户有一个I/O设备(如UART)。本来库函数fputc()是把字符输出到调试器控制窗口中去的,但用户把输出设备改成了UART端口,这样一来,所有基于fputc()函数的printf()系列函数输出都被重定向到UART端口上去了。下面是实现fputc()重定向的一个例子: externvoidsendchar(char*ch); intfputc(intch,FILE*f) {/*e.g.writeacharactertoanUART*/ chartempch=ch; sendchar(&tempch); returnch; }这个例子简单地将输入字符重新定向到另一个函数sendchar(),sendchar()假定是一个另外定义的串口输出函数。在这里,fputc()就好像目标硬件和标准C库函数之间的一个抽象层。 在C语言库函数中禁用Semihosting 在一个独立的嵌入式应用程序中,应该不存在SemihostingSWI操作。因此,用户必须确定在所有调用到的库函数中没有使用Semihosting。为了保证这一点,在程序中可以引进一个符号关键字_use_no_semihosting:在C代码中,使用#prgrama#pragmaimport〈_use_no_semihosting_swi〉在汇编程序中,使用IMPORT IMPORT_use_no_semihosting_swi 这样,当有使用SWI机制的库函数被连接时,连接器会进行报错: Error:Symbol_semihosting_swi_guardmultiplydefined 为了确定具体是哪一个函数,连接时打开-verbose选项。这样在结果信息输出时,该库函数上将有一个_I_use_semihosting_swi的标记。 Loadingmembersys_wxit.ofromc_a_un.1. Definition:_sys_exit Reference:_I_use_semihosting_swi 用户必须要把这些函数定义成自己的执行内容。有一点需要注意,连接器只能报告库函数中被调用的Semihosting,对用户自定义函数中使用的Semihosting则不会报错。 根据目标硬件定制存储器映射分散装载(Scatlerloading) 在实际的嵌入式系统中,ADS提供的缺省存储器映射是不能满足要求的。用户的目标硬件通常有多个存储器设备位于不同的位置,并且这些存储器设备在程序装载和运行时可能还有不同的配置。 Scattertoading可以通过一个文本文件来指定一段代码或数据在加载和运行时在存储器中的不同位置。这个文本文件scatterfile在命令行中由-scatter开关指定,例如: armlink_scatterscat.scffilel.ofile2.0 在scatterfile中可以为每一个代码或数据区在装载和执行时指定不同的存储区域地址,Scatlertoading的存储区块可以分成二种类型:装载区:当系统启动或加载时应用程序的存放区。执行区:系统启动后,应用程序进行执行和数据访问的存储器区域,系统在实时运行时可以有一个或多个执行块。映像中所有的代码和数据都有一个装载地址和运行地址(二者可能相同也可能不同,视具体情况而定)。在系统启动时,C函数库中的__main初始化代码会执行必要的复制及清零操作,使应用程序的相应代码和数据段从装载状态转入执行状态。 1.scatter文件语法 scatter文件是一个简单的文本文件,包含一些简单的语法。 My_Region0x00000x1000 { thecontextofregion } 每个块由一个头标题开始定义,头中至少包含块的名字和起始地址,另外还有最大长度和其他一些属性选项。块定义的内容包括在紧接的一对花括号内,依赖于具体的系统情况。一个加载块必须至少含有一个执行块;实践中通常有多个执行块。一个执行块必须至少含有一个代码或数据段;这些通常来自源文件或库函数等的目标文件;通配符号*可以匹配指定属性项中所有没有在文件中定义的余下部分。 2.简单分散加载样例图8 所示样例中,只有一个加载块,包含了所有的代码和数据,起始地址为0。这个加载块一共对应两个执行块。一个包含所有的RO代码和数据,执行地址与装载地址 相同;同时另一个起始地址为0x10000的执行块,包含所有的RW和ZI数据。这样当系统开始启动时,从第一个执行块开始运行(执行地址等于装载地 址),在执行过程中,有一段初始化代码会把装载块中的一部分代码转移到另外的执行块中。下面是这个scatter描述文件,该文件描述了上述存储器映射方式。 LOAD_ROM0x4000 { EXE_ROM0x00000x4000;Rootregion { *〈+RO〉;Allcodeandconstantdata } RAM0x100000x8000 { *〈+RW,+ZI〉;Allnon-constantdata }} 3.在分散文件中放置对象在大多数应用中,并不是像前例那样,简单地把所有属性都放在一起,用户需要控制特定代码和数据段的放置位置。这可以通过在scatter文件中对单个目标文件进行定义实现,而不是只简单地依靠通配符。为了覆盖标准的连接器布局规则,我们可以使用+FIRST和+LAST分散加载指令。典型的例子是在执行块的开始处放置中断向量表格: LOAD_ROM0x00000x4000 { EXEC_ROM0x00000x4000 { vectors.o〈Vect,+FIRST〉 *〈+RO〉} ;moreexecregions... }在这个scatter文件中,保证了vextors.o中的Vect域被放置于地址0x0000。 4.RootRegion(根区) 根区是一个执行块,它的加载地址与执行地址是一致的。每个scatter文件至少有一个根区。分散加载有一个限制:创建执行块的代码和数据(即完成复制和清零的代码和数据)无法自行复制到另一个位置。因此,在根区中必须含有下面的部分: _main.o,包含复制代码/数据的代码;连接器输出变量$$Table和ZISection$$Table,包含被复制代码/数据的地址。由于上面两个部分的属性是只读的,因此他们被*〈+RO〉通配符语法匹配。如果*〈+RO〉被用在了非根区中,则在根区中必须显式地指明另一个RO区域。下面是一个例子: LOAD_ROM0x00000x4000 { EXE_ROM0x00000x4000;rootregion { _main.o〈+RO〉;copyingcode *〈Region$$Tabl0e〉;RO/RWaddressestocopy *〈ZISection$$Table〉;ZIaddressestozero } RAM0x100000x8000 { *〈+RO〉;allotherROsections *〈+RW,+ZI〉;allRWandZIsections }} (待续)在下期中将更详细介绍利用scatter文件进行存储器配置的方法,以及系统启动和初始化的过程和存储器映射变化关系。
本文地址:http://www.45fan.com/bcdm/70925.html