hadoop学习笔记知识点分析
1.hadoop作为分布式计算平台,具体可参见hadoop网站.http://lucene.apache.org/hadoop
在学习windows下部署过程中遇到不少问题,在这里把学习的一点心得写出来,希望在学习的朋友
能少一点走的弯路.
2. hadoop 组成
hadoop 由两部分组成 分布文件系统 hdfs,分布计算框架map/reduce ,在这里先主要介绍其hdfs部分.
3. 系统中的实现
3.1 数据存储
在HDFS文件系统中存在NameNode和DataNode节点,其中NameNode系统中存在一个,用来存储各DataNode中包含数据块信息.
具体对应关系如下.
1.文件对应的块信息
2.数据块—对应的机器列表 简称为B-M表
如 blk_010100010 – machine1
blk-010010001 – machine 2
这个数据表是根据从数据节点提交的信息,动态建立的.
数据节点中存放块信息.
3.2NameNode节点与DataNode节点交互
NameNode开启时,会产生一个Rpc调用的Server,作为与数据节点交互提供服务.具体由系统实现的一个简单的Rpc实现模型IPC完成.如下图
图1

在IPC Server上默认开启10个线程接受来自客户端的调用请求. 另一方面在NameNode开启过程中会启动一个内嵌的httpp server jetty.从上图我们可以看到系统启动在10.0.128.129:50070上启动一个http server,我们可以通过当前的地址访问到整个集群的工作以及使用情况.只需键入http:// 10.0.128.129:50070即可查看.如下图
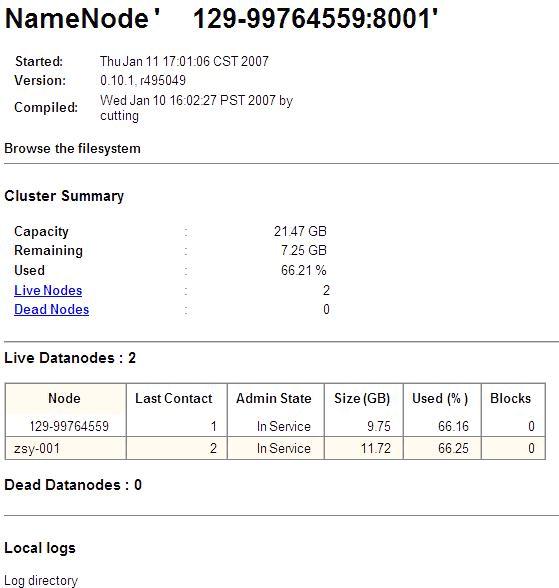
在这里我们可以看到整个集群中节点个数,以及每台数据节点的使用情况以及是否正常运行等信息.
从上图中我们可以看出通过此开启的http server我们可以对集群中当前存在的NameNode以及DataNode信息,以及磁盘使用情况等.在windows下获取的为当前工作项目所在磁盘的使用情况.
NameNode启动后,我们就可以开启DataNode,在DataNode开启过程中,数据节点根据配置文件fs.default.name节点中配置的NameNode地址(格式为host:port),进行连接.连接过程中DataNode会把自身具有的数据块信息发送给NameNode,NameNode根据数据节点发送的信息动态更新在NameNode节点上维护的B-M表.
本文地址:http://www.45fan.com/dnjc/73513.html